
本文转自@灾备有道,作者:Q先生。
核心指标:RTO,RPO
RTO(Recovery Time Objective)
RTO是指灾难发生后,从IT系统崩溃导致业务停顿开始,到IT系统完全恢复,业务恢复运营为止的这段时间长度。RTO用于衡量业务从停顿到恢复的所需时间。RPO(Recovery Point Objective)
IT系统崩溃后,可以恢复到某个历史时间点,从历史时间点到灾难发生的时间点的这段时间长度就称为RPO。RPO用于衡量业务恢复所允许丢失的数据量。
我们来举个例子,假设在业务系统正常运行的情况下,随着时间的推移,会持续产生新的业务数据。IT运维人员考虑到业务的重要性,小心又谨慎,写了个脚本对业务系统进行周期性的备份。
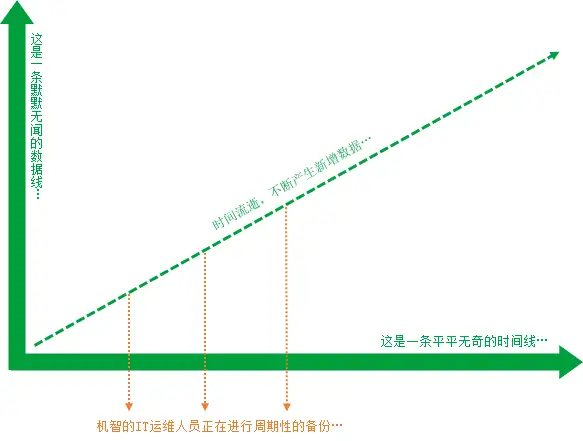
虽然机智的IT运维人员已经非常小心,但是还是避免不了系统出现故障。在发现系统故障后,IT运维人员迅速响应,利用最近一次的备份数据进行恢复。经过漫长的等待,IT系统最终恢复正常。
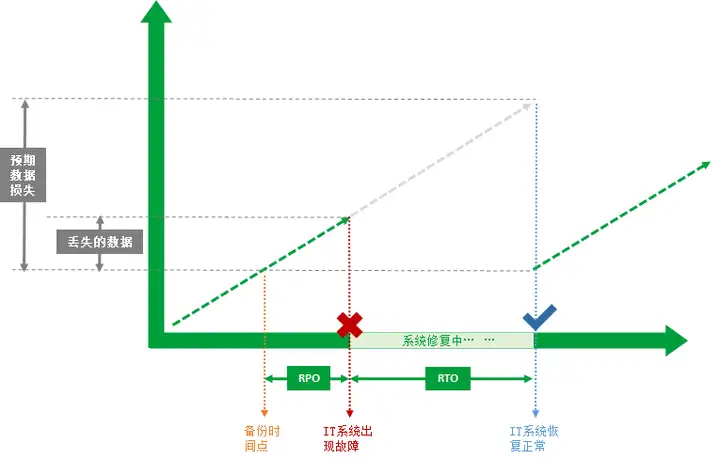
从上图可以直观看出,RPO是 “备份时间点” 到 “IT系统出现故障” 的时间长度,RTO是指 “IT系统出现故障” 到 “IT系统恢复正常” 的时间长度。
在RPO的这段时间内,存在一部分实际数据的丢失,所以一般认为RPO越小,丢失的数据量就越小。在RPO+RTO的这段时间内,本来有预期的业务数据增长,但由于IT系统故障需要时间修复,这部分的预期增长就损失掉了。可见RTO+RPO越小,对业务营收的损失也就越小。因此,越重要的业务越需要保证RPO和RTO趋近于0,当然所需要的投入也就越大。RPO和RPO也成为衡量灾难恢复的最核心指标。
随着灾备技术的不断升级,灾备系统的建设越来越复杂,就开始出现了一些新的指标。虽然这里边部分指标实在是不怎么知名,但为了满足大家的好奇心,还是费点周折,给大家解释一下。
RRO(Recovery Reliability Objective)
恢复可靠性指标RRO,用于衡量业务恢复的可靠性。如果一个业务连续性系统在10次恢复/切换中出现了2次失败,那么这个可靠性就只有80%。虽然成功的恢复/切换可以帮助你短时间内的恢复业务,但如果恢复/切换失败了,那可能就需要花更多的时间来排查和解决问题。因此,将RRO和RTO结合起来可以更好的评估灾难恢复的时间。
基于上面的案例,假设IT运维人员写了不错的备份脚本,但是恢复脚本没有经过详细的测试,质量不咋滴。在IT系统修复过程中,总出现恢复失败的情况,需要边定位失败的原因边进行恢复。那么我们就可以认为这个脚本的RRO指标很低,会导致RTO变长。RIO (Recovery Integrity Objective)
当灾备系统因为逻辑错误或数据丢失,就会造成实际恢复/切换的数据同样存在逻辑错误,或者数据丢失/不完整的情况。因此,单独的RPO不能保证灾备系统对数据丢失的防范能力,故引入恢复完整性指标**RIO**。RIO指标可以反映出业务系统灾难恢复到某个正确完整的状态的能力。基于上面的案例,假设IT运维人员写的备份脚本也出了问题,数据恢复是恢复出来了,但是只恢复了一部分,还有一部分数据因为脚本存在bug漏备了。那么我们就可以认为这个脚本的RIO指标也很低,RPO数据丢失的基础上再添损失。 说到这里,可怜的IT运维人员背了锅,也许你该考虑采购专业的灾备产品了。
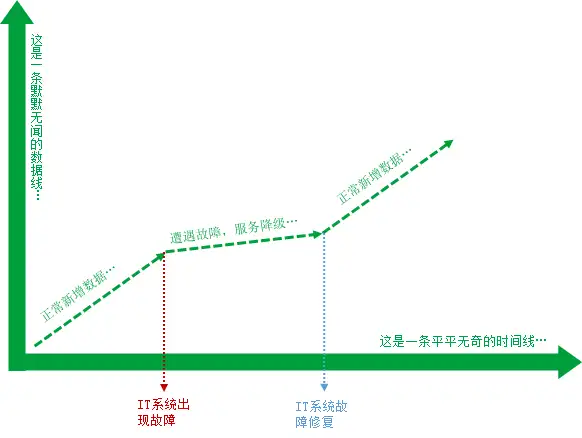
DOO(Degraded Operations Objective)
DOO 是指灾难事件发生期间数据中心不可用时,关键业务系统在灾备中心运行的服务级别允许降低到一个可接受程度。这意味着灾难事件发生时,为了加快恢复速度,可以允许关键业务恢复到一个较低的服务级别,这个事先确定的允许降低的服务级别就是 DOO。
服务降级一般是由IT系统本身提供的能力,并不由灾备厂商来提供,当然专业的业务连续性管理也会将IT系统本身的容错、服务降级能力考虑在内。
NRO(Network Recovery Objective)
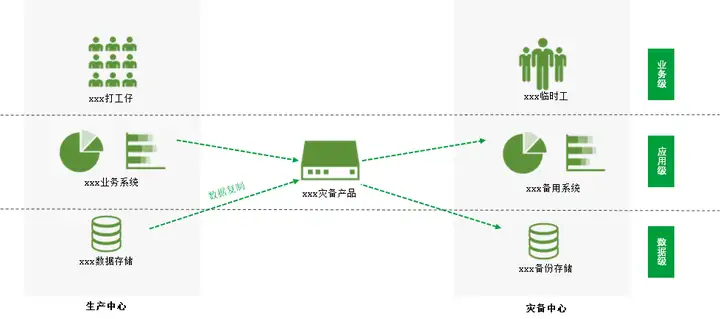
网络恢复目标NRO 是指在灾难发生后切换到灾备中心所需的时间。在这一预定时间内不仅要求将网络连接从数据中心切换到灾备中心,还要使用户的网络访问能够成功地转移到灾备中心。在行业中,一般认为灾备分为3个等级:数据级灾备、应用级灾备、业务级灾备。其中数据级和应用级的灾备一般都在IT系统的范畴,可以通过专业的灾备产品做到。业务级灾备在数据级、应用级的基础上,还需要对IT系统之外的因素进行保障,比如办公地点、办公人员等等。
数据级灾备的关注点在于保证用户的数据不会丢失或者遭到破坏。高级的数据级灾备会考虑将本地的通过某些手段(人工/灾备工具)保存到异地。而应用级灾备更强调实际的IT系统可以在遇到灾难后能够直接接管。一般来讲应用级灾备需要在异地灾备中心有完整的设备、网络条件,借助专业灾备产品做到生产中心到灾备中心的数据同步。
国际标准SHARE78的七级灾备
目前,通用的灾难恢复标准采用的是 1992 年在 AnaheimM028 会议上制定的 SHARE78 标准。根据定义,灾备方案可以根据以下主要方面所达到的程度而分为七级:
Tier0 层:没有异地数据 (No off-site Data)
即没有任何异地备份或应急计划。数据仅在本地进行备份恢复,没有数据送往异地。Tier1 层:PTAM 卡车运送访问方式 (Pickup Truck Access Method)
异地备份 , 能够备份所需要的信息并将它存储到异地。PTAM 指将本地备份的数据用交通工具送到远方。这种方案相对来说成本较低,但难于管理。Tier2 层:PTAM 卡车运送访问方式 + 热备份中心 (PTAM + Hot Center)
相当于 Tier1 再加上热备份中心能力。热备份中心就是指在异地制定相应的灾难恢复计划,将运送到此处的数据定期的进行恢复,以确保生产中心出现灾难后热备份中心可以尽快接管。当然,热备份中心拥有足够的硬件和网络设备去支持关键应用。Tier3 层:电子链接 (Electronic Vaulting)
在 Tier2 的基础上用网络传输取代了卡车进行数据的传送。Tier4 层:活动状态的备份中心 (Active Secondary Center)
指两个中心同时处于活动状态并同时互相备份。在这种场景下,两中心通过备份软件系统进行周期性的备份和恢复。在灾难发生时,关键应用的恢复也可降低到小时级或分钟级。Tier5层:两个活动的数据中心,确保数据一致性的两阶段提交(Two-Site Two-Phase Commit)
它提供了更好的数据完整性和一致性。Tier5 要求两中心的数据能够同时更新。在灾难发生时,仅是传送中的数据被丢失,恢复时间被降低到分钟级。Tier6 层:0 数据丢失 (Zero Data Loss),自动系统故障切换
Tier6 可以实现 0 数据丢失,是灾难恢复的最高级别,在本地和远程的所有数据被更新的同时,利用了双重在线存储和网络切换能力,当发生灾难时,能够提供跨站点动态负载平衡和自动系统。相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



