
从零建设一个可容纳万台服务器的数据中心网络需要多久 ?这更像是一个“要把大象装冰箱, 总共分几步 ?”的问题。
传统方式从零开始建设一个数据中心, 网络从建设到交付的过程像是“开荒”,繁琐的网络设备命令依赖工程师人工编写,费时又费力,并且交期与质量均无法得到保障。
为此我们设计了一款数据中心网络建设系统 —— Big Bang。将数据中心网络开局这一任务切分为 “架构规划”、“资源分配”、“配置生成及下发“ 三个步骤。每一步之间耦合松散而内部又高度内聚,实现低成本适配不同版本架构迭代、不同规模机房的小时级快速部署目标。
Big Bang 上线后支持了优刻得自建的乌兰察布大规模数据中心网络建设开局。至今已完成海内外多个机房的快速、高质量交付。
The Big Bang Theory : 宇宙是由一个致密炽热的奇点于一次大爆炸后膨胀形成的。1. 上一代建设系统的不足
在 Big Bang 之前 UCloud 物理网络团队已经在运营一代数据中心建设系统, 随着业务和架构的演进, 上一代系统的一些缺点逐渐暴露出来 :
对多平面的 Fabric 数据中心网络支持不够灵活;架构规则描述不灵活, 网络设计版本迭代后,需要再次投入大量研发人力适配,且存在需要研发理解网络业务设计的强耦合问题;原子命令库方式组织的配置模板不直观,人工难以预测其生成的配置,导致维护成本过高,且修改后无测试,容易出错;在建设海外机房时,由于网络延迟过高,基于编排器的配置下发方式出现了失败率快速攀升的问题。通过上述问题的分析不难得出推论, 我们需要这样一款建设系统 :
灵活适配多版本、多形态、多平面的数据中心网络;网络架构迭代不应需研发同学介入;可以直观的修改配置模板,修改后可以自动化的低成本的进行测试;低网络依赖,弱网条件下依然能好用。2. Big Bang 设计概要
2.1 人肉运维之痛
在谈设计之前, 我们先来谈一下人工建设一个数据中心会遇到哪些挑战 ?
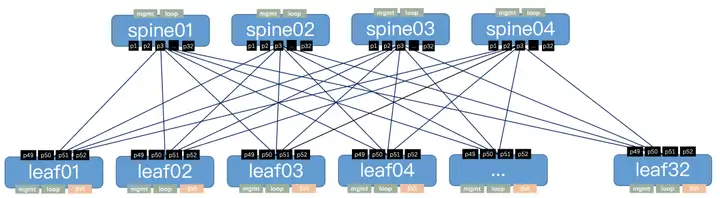
考察一个简单的两级 CLOS 架构 : 4 个 Spine, 32 个 Leaf 共 36 台设备构成一个业务专区, 这在 UCloud 数据中心中是很常见的 POD 规模。
建设这样一个网络, 首先需要给出设备接线表交由现场的同学进行布线。这张接线表要表达 “spine01.p1 接 leaf01.p49, 使用 QSFP28 100G 线缆” 这样的信息. 对于这个 POD 便产生了 4 * 32 = 128 个互联关系。
给出布线规则后, 我们再来考虑 IP 分配的问题。
图中每一条线均需要一对互联地址, 除此之外设备还需要分配管理地址、业务地址等。一个 POD 便需要 128 个互联网段、32 个业务网段、几十个管理地址。这些地址都需要工程师到 IP 管理系统中占用, 并与设备 ( 互联关系 ) 一一对应.
可以看到, 在 CLOS 架构下进行的互联计算、资源分配工作非常繁复, 并且数量会随着网元数量、接口数量的增加而急剧增加。
除此之外,还有一些要求会使这些挑战变得更加复杂:部分角色指定接线规则,如何分配端口?跨机房设备的线缆 / 模块如何选取对应物料?
接下来考察实际的配置。
有些配置是所有角色共有的, 如生成树配置、AAA 配置等. 而有些配置又会根据设备角色的不同而有所区分, 如 DSCP 标记、三层接口等。
当引入了多设备厂商, 情况会变得更复杂:
接口名是 100GE 还是 Hundred Gigabit Ethernet ? slot / interface / index 是从 0 开始还是 1 开始 ? 去使能某个功能的关键字是用 undo 还是 no ?建设团队的工程师会维护多角色、多厂商配置模版文件, 一般以 Excel / 文本文件的形式呈现。对某一特定设备开局时需要跳转多个文件, 进行不断的 copy / paste 来完成一个设备的配置编写。
如此, 完成一个几百台网络设备的数据中心网络开局, 可能需要 1 - 2 个人 / 周投入, 这显然不能满足业务快速扩展的需求。
2.2 Automate or die
不难发现, 整个开局过程中有大量繁复的计算和操作工作:
繁杂的接线分配、IP 地址分配工作重复的配置文件的翻译工作服务于架构角色的配置区分人工进行这些繁复的工作,效率很低且容易出错, 而这正是程序擅长的。
2.3 系统分层设计
回到之前的问题 : 建设一个新的数据中心网络总共分几步 ?对整个建设过程进行考察和思索, 将过程抽象为如下三个过程, 对应大爆炸系统的三个组件 :
1. 规划 - 架构规划库
类似《GB 50017-2017 钢结构设计标准》, 这是一个抽象的实施规范,如 UCloud 可支撑单可用区 320,000 服务器的数据中心网络系统设计。
2. 分配 - 资源分配器
类似有建设需求后, 拿到了一块地开始计算需要哪些物料, 分配各项资源,并抽象生成连接图。
3. 建设 - 配置生成及刷入
类似拿着图纸进行施工,直到把楼盖好交付,生成出所有设备的配置文件, 刷入设备中。
这样做的好处 :
耦合松散, 每一个模块只完成一个或几个功能, 彼此通过结构化的信息进行流转, 彼此屏蔽了内部细节;当其中的一小部分发生变化时,只需要修改发生变化的部分。如机房现场需要更换接线表的格式,只需要发布一个新版的资源分配器。上下游不需要感知资源分配器发生变化。3. 架构规划库
如果需要程序来计算需要的设备、互联图、IP 段等信息,首先需要考虑的是:“应该如何抽象的表达一个架构?”
先退一步,我们应该如何描述一个机房的拓扑?
这要求我们描述一个图结构 :
点:有哪些设备线:设备物理上是怎么互联的点及线的属性:IP基于此,我们再进行一次抽象,把具体每个设备的抽象为角色,把具体的 IP 变为可分配的 IP 段。然后得到我们需要描述的内容:
有哪些角色(设备)有哪些 IP 段可供分配角色之间是如何互联的角色本身(如 loopback 口)要使用哪些 IP 段互联要使用哪些 IP 段因为
一个较小的 IP 段肯定是由一个更大的 IP 段拆分而来,分出来的子 IP 段有关联。我们需要多个角色通力合作才能连通网络,角色之间有关联。基于上面这些假设,我们可以抽象出两棵树————设备树和 IP 段树,这二棵树各自扇出(fan out) ,最后在叶子节点上建立关联。
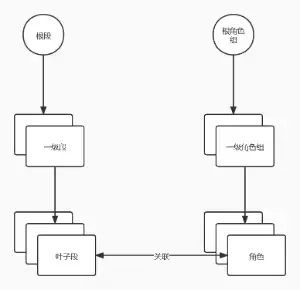
至此,我们已经表达了:
有哪些角色有哪些 IP 段角色本身(如 loopback 口)要使用哪些 IP 段这三个信息点。
还剩下:
角色之间是如何互联的角色之间的互联要使用哪个 IP 段这两个信息点。
在数据中心网络演进到多平面的 Fabric 网络后,互联关系的种类呈现指数级上升。如何准确、易理解、低成本、低耦合的描述这些互联关系成为了摆在我们面前的巨大难题。
我们想到的第一个方案:预定义套餐,即预先定义出所有可选的互联方案。将这些逻辑固化到代码中去。如:笛卡尔积式互联,间隔互联,交叉互联等等。
我们迅速否决了这个方案,因为:
极高的理解成本:工程师很难从名字和描述等处获得足够的信息,需要配套大量的文档,相当于回退到了文档描述的时代。极高的研发成本:每当新加一种互联类型,都需要大量研发资源投入适配,也需要研发同学深入的理解每种互联方案,再加上每种互联方案有大量的可调参数,如间隔步长等。严重的跨模块耦合:当架构规划信息在“架构规划库” 和 “资源分配器” 之间传递时,需要为每个互联方案设计一种数据结构,相当于要求“架构规划库”和“资源分配器”都需要完全理解每一种互联方案。我们从 tcpdump 工具中得到启发,当要描述特定领域内的复杂逻辑的时,可以尝试设计一种 领域特定语言(DSL)来解决。我们设计了一种描述互联的 DSL ---- UCLOUD DC CONNECT LANG 。语言短小精悍,说明文档约一页,描述一种互联关系只需要 10 个左右的字符,实践中,新员工只需要大约 1 天就可以理解这个语言,这个方案完全解决了预定义套餐产生的问题:
极低的理解和维护成本:只要理解了这个语言,就理解了所有的互联方案。极低的研发成本:只需要实现了这个语言的逻辑,就可以覆盖所有的互联方案。所以,“资源分配器”只需要实现一次语言逻辑,终身免维护。极低的耦合:架构规划库直接向资源分配器按 string 传递 DSL 原文即可,不再需要多种数据结构。回到之前的“两棵树”上,给角色之间补充上互联信息和互联需要使用哪些 IP 地址段的信息。
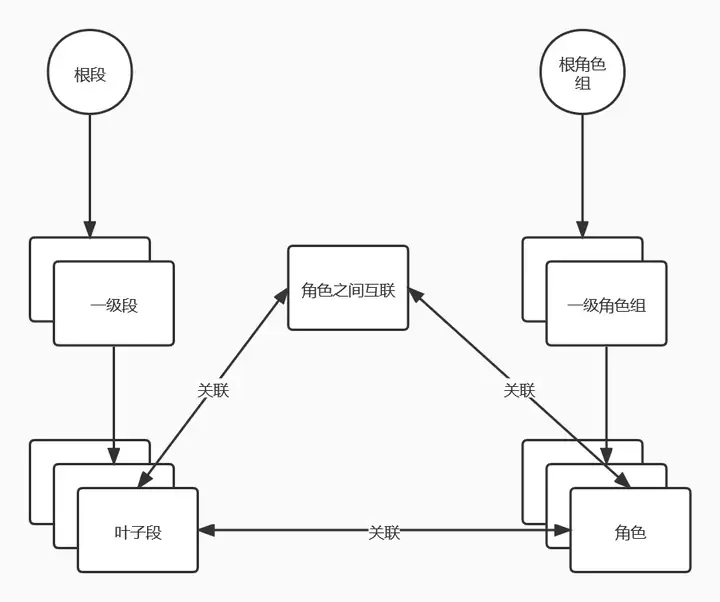
至此,我们通过两棵树和一个三角形已经完整表达之前提到的五个信息点:
有哪些角色(设备)有哪些 IP 段可供分配角色之间是如何互联的角色本身(如 loopback 口)要使用哪些 IP 段角色之间的互联要使用哪些 IP 段当然实际上还要稍微复杂一些,诸如 IP 段上会有业务标签,角色上会有端口分配规则等等。但这些本质上只是各个叶子节点的其他属性,只需要简单的加到叶子节点上即可。
4. 资源分配器
架构规划库的信息流转到资源分配器后,资源分配器就要来分配资源。
那么第一个问题就是:它需要分配什么资源?
我们的答案:分配那些需要在全网资源池中获取的,与具体架构及具体路由协议无关的资源。
这样做的主要原因是我们希望资源分配器与网络架构设计完全解耦,否则会导致:
要么,需要持续投入研发人力跟踪实现数据中心内的动态路由协议从 OSPF 到 BGP 再到分布式数据库所需的各种资源分配逻辑。(开发工具的同学不见得可以低成本、快速地理解网络设计上的细节。)
又或者,系统能力限制网络架构设计,若系统只支持 BGP AS 号分配,那架构设计只能使用 BGP 协议那这些协议相关的逻辑资源怎么办?我们借鉴了“变量作用域”的概念。
资源分配器为每个角色分配一组局部(包括但不限于数据中心内、设备组内等)唯一的 ID 值,我们称之为 ID 组。在下一步配置生成中再根据 ID 组计算出这些资源。
这样的设计保证了:
局部唯一性可计算性,互联两侧角色可以根据同样的参数和算法得到同样的逻辑资源,使得路由协议能正确协商确定了需要分配的资源后,资源分配器根据架构规划库给出的架构信息,人工给出的规模信息,从 CMDB、IPAM 等资源池中获取设备、IP等资源,并计算出一个描述了整个数据中心拓扑的数据文件,称为连接图。
连接图中的信息主要包括两类:
1)设备信息(点)
上文提到的 ID 组管理 IP…2)互联信息(线)
两侧设备两侧 IP两侧端口…连接图信息将会继续传递给配置生成器。
5. 配置生成器
至此, 我们已经有了基于架构规划库给出的规则分配好的资源(连接图信息), 这些信息如何转化成交换机可以理解的配置 ? 这就是配置生成器做的工作。
5.1 配置的生成
实际写到交换机上的命令可以分为三大类 :
全局一致的配置, 如 AAA 配置、安全策略配置等与角色自身属性有关的配置角色之间的互联配置,如 BGP peer address、BGP AS 、三层口 IP 等一个配置例子:
可以发现,配置实际上是由一些固定的模板及变量组合而成的。而这些变量肯定来自于资源分配器的连接图中,点自身的属性,或者线的属性,又或者是与点连接的另外的点的属性。所以,只需要写好模板,再遍历连接图,我们就可以很轻松地得到整个机房所有设备的配置。
上文的配置在模版中的表现形式 :
我们使用 jinja2 来帮助渲染模板,jinja2 支持模板的继承和组合,可以避免在每个角色的模板中重复写很多通用配置。同时,jinja2 模板非常的直观,简洁,所见即所得。替换为 jinja2 后大幅降低了配置命令的错误率。
我们还通过 git 管理模板,并围绕 git 构建了模板编写及修改工作流,引入了自动化测试机制,保证了对模板的修改有解释,有review,且经过测试,基本消除模板语法错误导致的沟通成本。
5.2 临门一脚
通过前述的资源分配等步骤, 至此我们已经完成了所有设备的配置生成工作, IDC 现场的同学也按系统给出的信息将设备完成上架、接线、开电。
至此我们只剩整个数据中心物理网络建设的“临门一脚”, 这些配置文件(以交换机 sn 命名的 txt 文件)如何下发到交换机上, 作为 startup config 启动并运行 ?
这里我们使用目前各主流厂商均支持的“零配置启动”功能 :
定义
ZTP(Zero Touch Provisioning)是指新出厂或空配置设备上电启动时采用的一种自动加载版本文件(包括系统软件、配置文件、License文件、补丁文件、自定义文件)的功能。
目的
在部署网络设备时,设备硬件安装完成后,需要管理员到安装现场对设备进行软件调试。当设备数量较多、分布较广时,管理员需要在每一台设备上进行手工配置,既影响了部署的效率,又需要较高的人力成本。
设备运行ZTP功能,可以从U盘或文件服务器获取版本文件并自动加载,实现设备的免现场配置、部署,从而降低人力成本,提升部署效率。
实际运行中, 我们会在新建的数据中心部署一台 PC (一个致密炽热的奇点), 这台 PC 上运行了 DHCP、TFTP 服务以及存放了该数据中心所有设备的配置文件。
类比服务器的 PXE 装机过程, 我们利用 DHCP 服务器下发 TFTP Server 和 Bootfile, 交换机会自动执行该脚本, 而后从 TFTP 服务器下载其所需的配置文件。
在这里我们之前忽略了一个问题 : 同一数据中心内采购多厂商的设备, 如何解决生成 / 下发特定厂商配置文件的问题?
答案是不解决, 或者说不在前期考虑这个问题。
配置生成器不感知, 也不在乎上架使用的具体设备型号, 而是直接生成出所有可能厂商的配置文件. 例如某一特定角色共有 A、B、C 三个厂商的三份配置文件。
在交换机发送 DHCP Discover 报文时携带其厂牌信息, 如此奇点只要根据其厂牌返回不同的 TFTP 路径即可完成配置的下发。
通过以上几个步骤, 在现场完成上架、布线等工作后, 我们可以在小时级别将整个数据中心内的配置拉起, 完成开局。
5.3 one more thing
完成配置下发并不是结束, 我们还赋予了“奇点”一些其他功能 : 因为有了整网的连接图, 我们可以在最终交付给业务之前做一些检查, 确认我们的数据中心网络是可靠的。
通过对所有设备的连通性检查, 确认设备均已正确上线, 管理面均可达。通过比对交换机的 startup config 与 running config , 确认全部配置下发正确。通过 ZTP 功能, 我们可以指定上线设备的版本信息, 由系统自动升级为 DCN 指定的操作系统版本.通过比对连接图中的 peer 关系与读取设备的 LLDP 信息, 确认全部接线正确。(在我们实际运行中此处常会检出一些错误 : 人工依然是不可靠的, 而工具可以检查和避免这种错误。)6. 总结
从零建设一个可容纳万台服务器的数据中心网络需要多久 ?
答案是:几小时。
比起“交付时间压缩了多少”, 更大的价值更在于我们将目光聚焦在工程师擅长的地方, 将其从繁琐的表格、分配工作中解放, 更多精力去理解用户的工作流和关注点, 打造真正能输出业务价值的网络基础设施。
UCloud 物理网络团队坚信“连接的力量”, 为各公有云产品、为客户提供更稳定、更高效的网络服务。
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



