
人工智能(AI)的兴起
人工智能经过50年的演变,正进入高速发展期,且越来越成为一种通用技术,深刻影响人们的生活和社会的进步。
数据显示,从2000年开始,全球人工智能企业的增速很快,总数达到了8107家,平均每天诞生约1.39家。透过数据发现,过去五年是人工智能发展的重要阶段:全球超过60%的人工智能企业诞生于过去五年间,在2012-2016年,全球人工智能企业新增5154家,是此前12年的1.75倍左右。
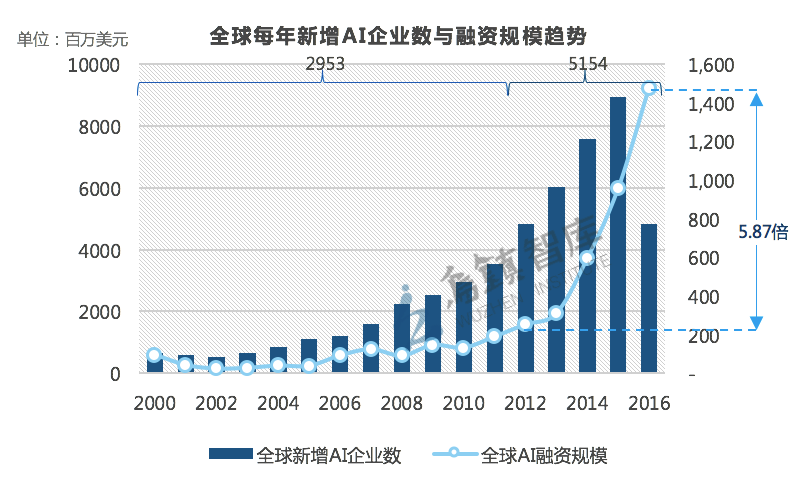
全球AI产业规模发展
--数据来源:乌镇指数2017
AI的发展对基础设施的要求
华为发布的《GIV 2025:打开智能世界产业版图》白皮书预测:2025年个人智能终端数量将达400亿,个人智能助理普及率达90%,智能服务机器人将步入12%家庭。全球1000亿联接将广泛用于金融、制造、交通、公用事业、医疗和农业等各个领域,推动数字化转型。届时企业应用云化率将达85%,AI利用率达86%,数据利用率将剧增至80%,每年1800亿TB的新增数据将源源不断地创造智能和价值。
可以确信,人工智能在将来几十年时间保持高速发展,而且将更加深远地影响整个科技、经济、社会发展。在不久的将来,很多原本由人完成的工作将由机器来完成,AI技术也会发展到一个新的高度。
AI的应用和服务,离不开数据中心的支持。从技术层面看,未来的AI数据中心将更大、更快:
规模更大:目前,很多AI应用已经在利用大数据、云计算平台获取海量数据进行计算,随着行业数据的不断整合、IoT等更大规模的数据源,单个AI计算系统的规模将不断扩大,未来的人工智能计算环境必然主要基于数据中心提供基于云平台的服务和接口。
计算更快:当前,主流服务器CPU能够提供1 TFLOPS左右的计算能力,且近年来CPU计算能力的增长进入瓶颈。相对的,近来的普通GPU芯片能够提供10 TFLOPS的计算能力,最新研制的AI专用计算芯片以及包含AI专用加速内核的GPU已经能够在功耗相近的前提下提供超过100 TFLOPS的运算能力,通过架构设计的变化打破了摩尔定律对AI计算的限制。有理由相信,未来的AI芯片能力还会快速增加,从而使得单个节点的AI计算能力达到一个前所未有的高度。计算能力的增加也对系统架构、网络架构和通信性能提出了更高的要求。
AI时代数据中心面临的挑战
AI时代数据中心规模更大,计算和存储更快,网络成为AI业务发展的瓶颈。数据中心网络在高带宽、低时延、少丢包等性能指标方面还存在较大差距,尤其在细粒度的单点控制、整网控制和软硬件结合的设计方面存在差距,无法全部满足未来AI应用对计算与通信高度并行的需求。
具体而言,AI时代的数据中心,尤其是分布式云数据中心在微突发流的控制、拥塞响应、负载均衡和混合流调度等场景面向巨大挑战:
Incast(微突发流)拉长通信时长:在分布式数据中心中,服务器集群内多个服务器同时访问1台服务器形成Incast(微突发流)成为了常态。数据中心网络现有常用流控机制(如PFC),无法保证不丢包,会造成部分流量的严重拖尾现象,拉长整体通信时长。
拥塞无法快速响应:分布式数据中心内突发流量大,需要响应时间短,而目前数据中心网络基于ECN(Explicit Congestion Notification) 显式拥塞通知标记方式的拥塞控制机制响应时间过长,容易造成欠吞吐或流量过冲问题,满足不了AI业务毫秒级突发大流量的拥塞控制需求。
缺乏高效的负载均衡机制: AI时代数据中心内因计算模型的缘故,AI应用交互产生的流量具有明显的模式特征,使得网络路径上的流量严重不均衡。目前数据中心网络主要基于流的负载均衡机制无法满足高带宽、持续大流量的负载均衡需求。
混合流无法基于优先级区分调度:分布式架构数据中心内数据流量是规模较大的大流(10M-100MB),而用于控制的流量都是小流(KB级别)。长时间频繁的大流通信会严重影响AI应用控制小流的通信。而往往控制小流的通信优先级更高,导致AI应用和训练效率降低。当前数据中心交换机和服务器网卡很少支持区分流的类别,比如数据大流和控制小流,使得控制小流因缓冲、头端堵塞、无高优先级调度而被动等待。
满足AI需求的智能无损网络
随着AI的发展和普及,存储介质、计算技术的提升,数据中心网络面临如上流控、拥塞响应、负载均衡和混合流调度等多方面的挑战。
为了应对挑战,华为CloudEngine 16800系列交换机首次创新性地引入AI芯片,构建面向AI时代的AI Fabric智能无损数据中心网络解决方案。
CloudEngine 16800通过AI芯片强大的处理能力,运行iLossless算法,实现独特创新的拥塞管理和流量控制,打造最快数据中心网络,引领数据中心迈入智能无损新纪元。
AI Fabric智能无损数据中心网络主要通过Incast微突发流量控制、流量属性智能识别调度、流量负载均衡和拥塞控制协同等四个方面,打造零丢包、低时延、高吞吐的极致性能。
无丢包、无拥塞的Incast微突发流控
内嵌AI芯片的CloudEngine交换机能实时动态的调整转发芯片缓存门限配置,打破传统交换机固定门限参数的局限,并根据流量模型变化自适应的调整缓存门限,有效应对分布式架构N打1的Incast微突发流,实现无丢包。
大小流的区分调度
CloudEngine交换机可以自动识别大小流属性,区分出数据大流后,对大流降级调度,以防止大流堵满队列,导致小流因丢包或加大时延,解决数据大流对控制小流的堵塞。
网络流量负载均衡
数据中心网络通常采用基于报文特征字段的静态哈希算法进行流量负载均衡。CloudEngine交换机一方面可以将数据大流“切割”成多个小流,提升负载均衡和链路带宽利用率;另一方面,哈希算法加入链路空闲因子,减少哈希不均衡的出现,使整网流量更合理地转发,链路重复利用。
拥塞控制协同
CloudEngine交换机可在报文队列遇到拥塞时,“出队”的报文立刻进行ECN(Explicit Congestion Notification)标记,避免传统ECN显式拥塞标记方式需要等到报文从“入队”到“出队”才开始拥塞通知。节省了一整个队列的拥塞时间差同时使报文发送端服务器网卡更快地响应拥塞并降速,及时缓解网络设备的缓存拥堵,从而有效降低时延,提升应用性能。
AI Fabric在金融行业的创新实践
AI Fabric智能无损数据中心网络解决方案已在多家企业进行了部署。
招商银行是部署华为AI Fabric解决方案的全球首个客户,该方案帮助招商银行提升分行云存储约20%的IOPS性能,助力招商银行加速向“轻型银行”、“零售金融3.0”转型。
AI Fabric解决方案可以应用于AI应用训练、分布式存储、高性能计算等多个数据中心典型场景,相比业界主流友商快30%,100%释放算力,降低TCO 53%,使能智能金融。
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



