
编辑|Emily AI
前线出品| ID:ai-front
Google 在过去十几年绝对是数据中心的发展上面是走在最前列的,在数据中心网络的发展上面绝对也是前列的,在 2015 年的时候 Google 把他们之前的数据中心的网络发展历史在 SigComm 上面公布了,我们今天可以来看看 Google 可以公开的老东西能给我们什么启发。
第一点,基于市场上已有的 switch 的材料来建立的 multi-stage Clos topologies 是可以支持一个很大的数据中心的网络需求的。
第二点,很多传统的,去中心化的,可以兼容各种不同的设置的数据中心内部网络对于 Google 来说绝对是太复杂了(这里潜台词是 Cisco 卖的东西很多功能 Google 用不到)。对于 Google 来说,它的数据中心都是提前计划好的,而且只有一个客户,就是 Google 自己。在这个前提下,把网络简中心化是有优势的。
第三,Google 自己设计的网络硬件和软件让他们可以支撑跨集群(inter cluster,我这个瞎翻译的)跟跨地域(wide-area,也是瞎翻的)的网络。这几个点在开头都讲到比较含糊,后面会具体解释每一个点是什么意思。
导言
网络在云计算的时代对于数据中心来说是非常重要的。对于 Google 来说,每 12~15 个月数据中心内的网络流量会翻倍。为什么需求增长这么快呢?
数据的大小在变,互联网上有很多的照片/视频。处理这些数据的算法在处理的时候需要帮运的数据就变得更多了
网络服务如果可以拿到更多的数据,更多的特征的话,返回给用户的结果会更好
公司内部的各种服务也会分享不同的数据,比如搜索跟广告
十年前,Google 发现了传统的数据中心的网络能力其实基本上就是卡在一个点上面:市面上能买到的最大的 switch 是多大。这些 switch 都能支持各种各样的协议,而且也不对数据中心的设置有任何的假设,而不是像数据中心里面所有的网络都是可以提前设置好的。很多市面上 switch 能够提供的功能对于 Google 来说是无用的,而且还特别地贵。
这些 swtich 还有一个问题就是在传统的 WAN 互联网结构里面,每一个 swtich 挂掉问题都是不好的,所以这些市面上的 switch 都为了高可用性做了不同的牺牲。如果如果网络硬件便宜而且每个 link 挂掉代价没有那么大,那么就不需要为了高可用性做什么牺牲,况且需要支持的网络协议也没有那么多了。
Google 在设计网络的时候遵守了下面几个大的原则:
Clos Topology:一种 multistage circuit stage network,具体解释戳这里:Clos network - Wikipedia 。它的好处就是在扩张的时候基本上可以扩张到随意大小,只限制在故障方面的考量跟具体能够控制这么多个 switch。虽然这个设计抗故障能力很强,但是在 fibre fanout 还有在多个代价差不多的路线上面去做 routing 这两个方面还是有挑战的。
Merchant Silicon:所有的网络硬件层面的设计用的都是市面上已有的解决方案,来做这个 switch,而且紧跟市面上最好的网络硬件的发展,及时更新。
Centralized control protocols:因为设计理念基于 Clos topology,在管理层面变得非常的复杂,这时候这些 switch 的控制就需要一个特定的系统来总体的统筹了。
背景介绍
04 年的时候 Google 里面的网络设计是长这样的
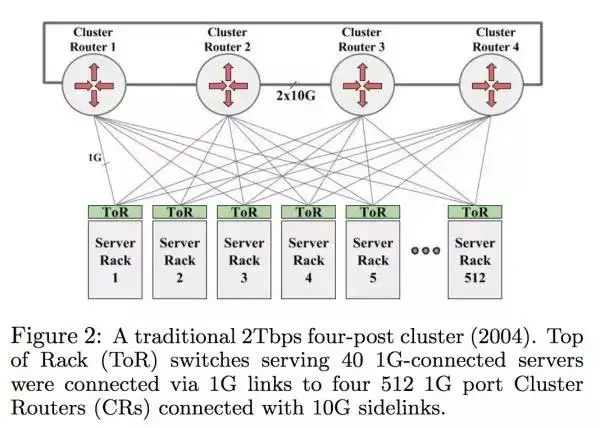
这个图片里面的 CR/Cluster Router 就是当时市面上最贵最好的 swtich,512 ports of 1GE。每个 rack 里面的机器都是连到 Top of the rack,然后 ToR 再跟 CR 沟通。这种网络架构最大的问题就是如果某一种服务需要很多的网络用量,那么必须确保绝大部分的网络都是在一个 rack 里面进行的,不然每个 CR 中间只有 2*10G,是不够所有人一起用的。这种设计在 ToR 跟 CR 之间我们叫 over subscribed。这个设计还有一个副作用就是每个集群必须要大,足够大来确保集群跟集群之间不需要网络沟通,这样等于是数据中心在设计的时候必须配合网络,不过大集群当然还有其他的考量,比如电流。
如果这些机器是一个储存服务,那么这个我们需要确保储存的数据不能在一个 rack/集群上面,不然会出现 correlated failure。但是如果要分散数据的话,就会需要用跟多的 CR 层面的网络,所以储存类服务需要常常跟其他的 rack 去沟通。
这个设计在当时是符合 Google 的内部需求的,但是总体的速度和价格还是不尽人意。每个 host 网络最多能用 100Mbps,丢包率也是很高(没说具体多高)。如果要增加带宽那么价格就会增加。这个时候他们了解到了现有的网络设计是没有办法继续扩张的,所以 Google 开始往 Clos topologies 上面移:
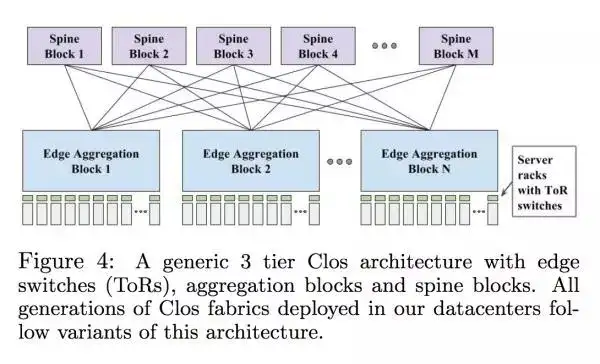
Google 当时遇到的最大的问题有下面几个
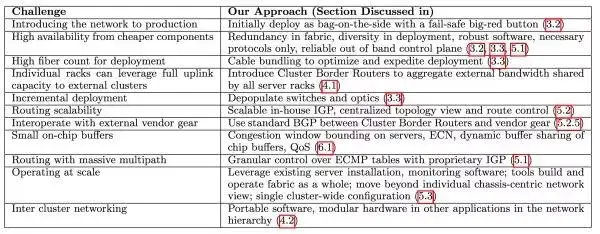
这个到后面我们会一个一个来解答。Paper 里面还提到了市面上还有几个可替换的解决方案比如 HyperX, Dcell,BCube 和 Jellyfish,这个大家有兴趣的话可以去看看这个 paper 的 reference。
Google 内部网络设计的进化史
下图是 Google 每个世代的网络架构的参数:

Firehose 1.0 一开始设计的时候主要就是为了能够支持在一个 10k 机器的集群里面,每个 host 有 1Gbps 的 nonblocking bisection bandwidth(看最右一栏 Bisection BW 从 2T 变成了 10T)。这个时代的最大的问题在于 ToR Switch 的基数比较低,每一对 ToR 之间的 link 断了之后这两个 rack 之间是不能沟通的,虽然能跟其他 rack 沟通。下图是 Firehose 1.0 的具体设计
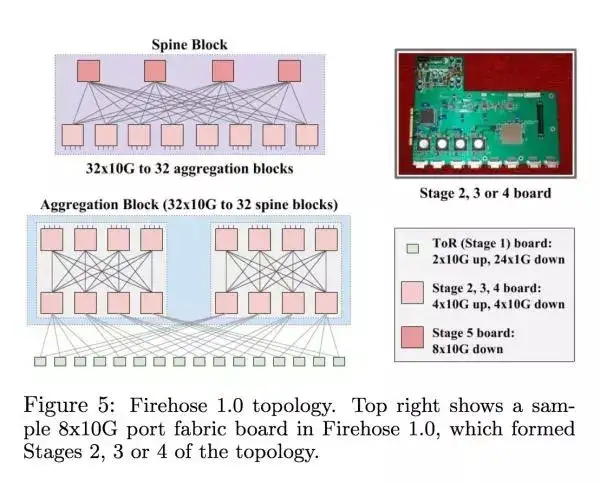
Google 当时在服务器设计端比较有经验,所以试过把 switching 的硬件通过 PCI-E 插到服务器上面。但是服务器常常挂掉/要被换,如果是负责 routing 的服务器挂掉的话整个 rack 都断网;由于这些缺陷 Firehose 1.0 从来没有进到 production。
Firehose 1.1: First Production Clos
1.1 跟 1.0 差别在于,swtiching 的逻辑不再是基于某一个服务器的了,而被放到了分开的一个盒子里面。用来控制这些网卡的网络是完全跟服务器的网络分离的。1.1 也为了确保整体每个 rack 的网络 over subscription 不超过两倍,每两个 ToR 被绑在了一起。每个 ToR 有 410G 跟 481G 的 link,这里面两条 10G 的 link 是连在 fabric 上面的,另外两条 link 连到了被绑定的 ToR 上面,每次每个机器的网络可以四条都用。Stage 2/3 的 swtich 是全部都连在一起的,而不是分开的两个 block。下图是 1.1 具体的设置

对于这个设计来说,连网线也是一大挑战,Google 当时的线主要是 14 米长,所以连的时候要事先计划好,所以还特地设计了 100 米的光纤让连线变得更容易。
Watchtower: Global Deployment
Firehose 1.1 的反响不错,但是当时没有把所有的集群都移到 firehose 上面。接下来继续在 Google 内部推的网络叫 Watchtower,主要差别在于解决之前连线的麻烦跟启用新一代 16*10G 的 switch 芯片。新一代的 chasis 跟内部设计长这样

大姐可以看到内部很多 linecard 都事先连接好了。新一代的 watchtower 也用 fibre bundling 来减少要连的线的数量,下图可以看到很多密密麻麻的线都变成一条大粗线了,而且还更便宜。
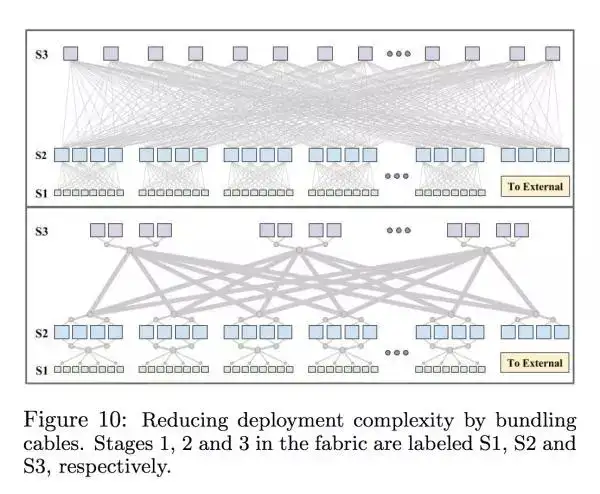
新一代的网络还是很贵,而且不是所有的服务需要那么多的网络的。为了减少开支,每次 deploy 的时候会先把 bisection BW 减半,如果还有更高的需求的话会再把线连上,这样可以减少光纤的开支。
Saturn: Fabric Scaling and 10G Servers
Saturn 主要差别是用了新的 24x10G 的硬件,以及更大的 chasis 跟密度更高。
Jupiter: A 40G Datacenter-scale Fabric
Junpiter 最大的进步在于要让整个数据中心内部的交流都是同样的 bandwidth,这样可以在网络层面消除在一个数据中心里面的软件需要考虑网络架构的问题,所以要不 Saturn 的 fabric 大 6 倍。而且因为网络的 scale 变得比以前大得多了,整体网络设计的时候需要更多考虑在系统故障的时候要如何处理。这一代网络的硬件从 2410G 变成了 4010G,而且现在所有的 aggregation block 都连上了 spine block
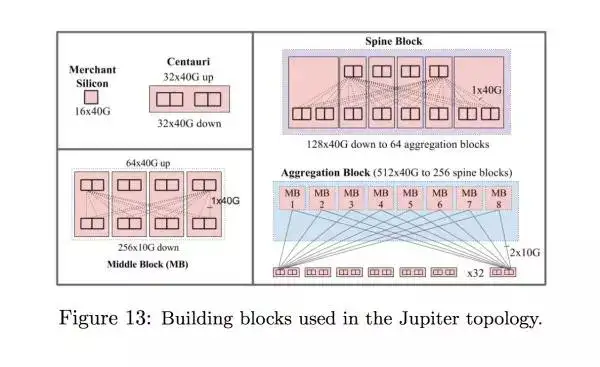
每个硬件的分割大小是一个 Centauri chasis,里面有四个 16*40G 的硬件,这个分割大小比 watchtower 要小,但是比 firehose 要大。这里还要注意为了确保 spine block 上有足够的冗余,有两个是没有连上的,不是图片出了问题。
从这一代网络开始,Google 内部的很多软件是不需要考虑网络的 locality 的问题了,因为整个数据中心的网络都是平的。这个绝对是划时代的网络架构。
外部链接
这里段是描述 Google 如何处理集群之间的网络,时间线在 Watchtower 跟 Saturn 之间,因为 Jupiter 这一代已经没有每个集群的网络分割了。当时有四个不同的选择可以让这个集群里面的机器连上外部的网络:
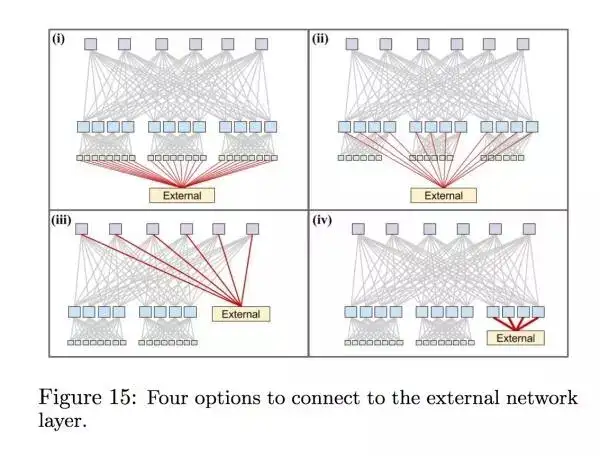
他们最后选择了第四个,这个选择对于他们来说跟安全,因为不想所有的 spine block 都连到外网上面。
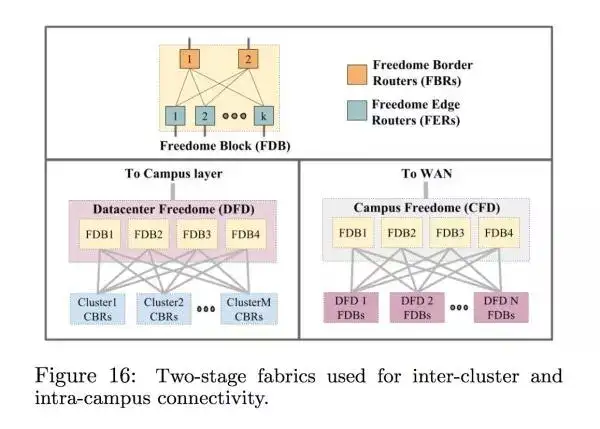
每个集群跟每个建筑物之间的网络都是跟之前的类似的层级
软件控制
一开始设计控制这些网络硬件的软件的时候就有一个问题,到底是用传统的,去中心化的 OSPF/IS-IS/BGP 这类算法来控制,还是中心化的通过定制的软件来控制这些硬件。传统的去中心化的算法最大的好处就是大家都知道而且稳定。Google 最后还是决定用定制的软件来控制,主要是因为下面几个因素
传统的算法不好控制多条相同代价的线路
十年前没有什么特别好的开源的 routing 解决方案
需要改动很多东西才能让 Google 自己设计的硬件去兼容不同的 routing protocol
这些去中心化的 protocol 常常需要用到 broadcast,在上百个甚至上千个 switch 的情况下这些 broadcast 是相当高的间接费用
需要能够直接的控制这些 switches
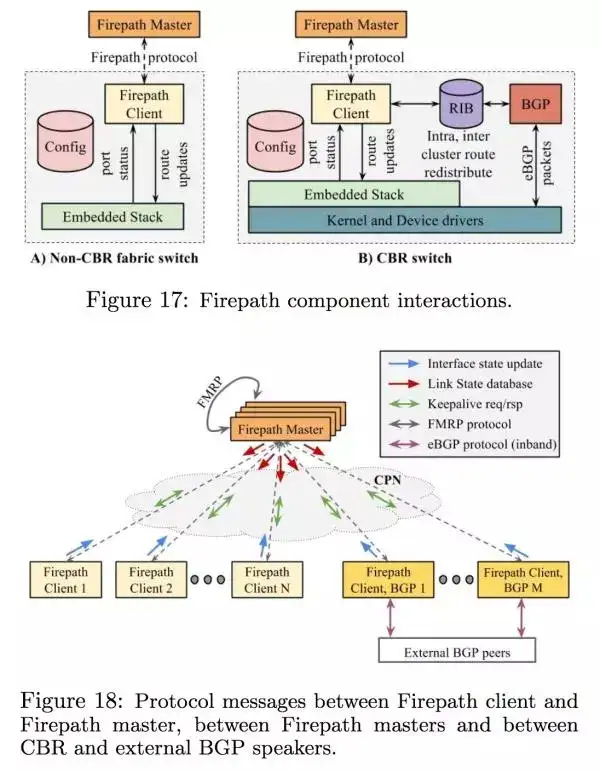
那 Google 内部网络的 routing 具体是怎么做到呢?这个 routing 算法叫 firepath,具体有下面几个步骤
每个 switch 都会自带一些数据来表达一开始设计的时候这个数据中心的网络拓扑具体是怎样的。通过跟邻居来沟通现在具体的拓扑是什么。
每个 switch 都会跟一个中心化的服务器沟通现在它的邻居的状态如何,中心化的服务器会处理现在所有 switch 汇报的信息然后再返回给所有 switch 最新的状态
switch 会根据中心化的服务器的信息,在本地计算现在应该如何 route
BGP 是在网络的边缘用的,跟外部沟通然后返回给中心服务器外部的状态
当然,这里提到的 Firepath master 是有冗余的,有 master election。这个 firepath 具体架构长这样
设置管理
在这么多 switch 的情况下设置管理也是不小的一个难点。Google 对网络设置的理念就是:把整个大的网络当成一个 static fabric,里面有已经设置好功能的 switch,而不是一个有 hierarchy 的网络架构。
在管理 switch 的时候,Google 把它当成一个非常普通的机器来对待:有警报,有 logging,还可以管理 image。下图是 Google 在 08 到 09 年各种不同的 switch 的故障原因

为了帮助网络人员维护,他们还改动了 traceroute 跟 icmp 让这些工具了解 Google 内部的网络架构,这样更容易知道哪里出了问题
经验之谈
Google 的网络硬件利用率达到 25% 的时候会开始变慢,这里面有各种这样的问题
网络利用本身比较 bursty
switches 的缓冲不够大
ToR 的 uplink 本身就是为了省钱而有 over subscription
flow hashing 做的不够好,特别是有故障的时候
他们用了几个方案来解决这些问题
设置 QoS,重要的网络优先级高
在 inter cluster 的时候服务器端的 tcp 被设置的不会塞满 switch 的缓存
在早起的网络硬件里面,确保每个 rack 不会超过自己 over sunbscribed 的网络太多
用 explicit congestion notification
如果有软件真的需要很多网络,改 uplink 的数量
每个硬件层面上的内存都是共享的,把这个共享机制改成动态的,这样忙的网络可以用跟多的内存
改动 hashing 来确保负载均衡是有效的
这些东西让整个网络在 25% utilize 的时候丢包从 1% 降到了 0.01%。
虽然停机出现的不多,但是这个网络系统还是出现过停机的状况,主要是因为
控制软件在大的 scale 下出问题
老旧硬件暴露出之前没暴露出的问题
设置错误(好吧这条我服气。。)
好啦,这里原文都讲完啦,接下来是我自己的理解跟观察。基本上最底层的网络芯片 Google 是不做的,估计是 broadcom 的芯片,跟 Cisco 那些硬件在芯片层面是没有差别的。这里 Google 为什么能够做成,他们很重要要考虑的事情其实是两点,数据中心网络的重要性和业界能给出的解决方案到底能让 Google 有多满意。
为什么数据中心的网络这么重要,我自己的观察是因为这是少有的在数据中心里面还可以有长足进步的维度。现在基本上单核的 CPU 速度进化已经不快了,当然总体 CPU 的速度还是在提升;内存这几年价格爆炸,基本上加内存也实际了;Flash 这几年价格也没便宜下来;更不要说 xpoint 或者 silicon photonic 这些 Intel 没边的科技了。这时候有一个可以有长足进步可能的网络层就变得尤为重要。
业界能给出的解决方案基本上说白了就是 Cisco 卖的东西能不能符合需求。在这数据爆炸的年代,向前问说的,这个在现有的数据中心里面是不够用的。Google 对网络的需求是 PB 级别的,那么这个时候就不是买上千个 Cisco 的 swtich 这么简单的事情了。当然,这个对于 Cisco 来说也不是最核心的生意,因为世界上像 Google 一样需要这么大的客户不多,思科现有的解决方案对于大部分公司来说还是相当好的。所以其实 Google 开心,Cisco 也无所谓,因为两个没有直接的竞争关系。
总体来说想要用 CPU 换内存或者拿内存换 CPU 来加速软件都是比较困难的决定。而且现在很多时候大家在意的不是一个机子要花费多少钱,而是这个数据中心电力供应能支撑多少机器,所以基本上在拿多少电力能换多少计算在未来几年是不会有什么特别的惊喜了。但是网络层就不一样了,数据中心内的网络的增长的速度过去这几年是爆发性的。而且最重要的是说网络层面的加速目前还是物理性的,如果真的需要加更快的速度可以通过连接更多的线,这些线未必会消耗多少电力,但是在数据中心其他维度的增长收到限制的时候,我们更多要思考的是这个网络速度上面的爆发能够给我们带来什么,这就是为什么我们要关心数据中心网络方面的发展。当年网络层面的紧张造就了 MapReduce,现在网络和内存层面的富余造就了 Dremel/Presto 以及各类 stream processing 的解决方案,这个都是不同时代的产物,而网络就是划分这个时代的最重要的因素之一。之后在内存不涨,CPU 不涨,储存不涨而网络层面继续增长的时代,我很期待还会有什么怪物系统出现,打烂我的三观。
原文戳这里
https://zhuanlan.zhihu.com/p/29945202
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43837.pdf
本文已由原作者授权转载
-全文完-
关注人工智能的落地实践,与企业一起探寻 AI 的边界,AICon 全球人工智能技术大会火热售票中,6 折倒计时一周抢票,详情点击:
https://aicon.geekbang.org/apply?utm_source=wechat&utm_medium=ai-front
《深入浅出TensorFlow》迷你书现已发布,关注公众号“AI前线”,ID:ai-front,回复关键字:TF,获取下载链接!
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



