大家好,我是老萧,好久不见。
今天想和大家分享一篇来自谷歌公司的论文,论文标题为 “Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Googles Datacenter Network”
(声明:本文截图均来自此论文)
这篇文章是由谷歌发表的一篇介绍型论文。为什么不是研究型论文呢?因为论文中并未提及任何实验以及相关数据;反之,该论文更像是历史课本,带领读者领略谷歌自家数据中心网络过去十年的发展历史,其中包括了:
集群内部网络架构(Intra-Cluster Network Architecture)所经历的五代变更第一代 —— Firehose 1.0第二代 —— Firehose 2.0第三代 —— Watchtower第四代 —— Saturn第五代 —— Jupiter集群外部网络架构(External-Cluster Network Architecture)的变更软件控制方案谷歌从数据中心发展中学习到的经验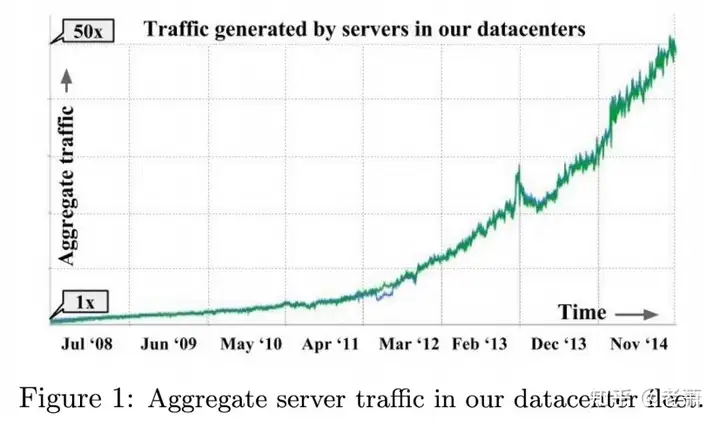
网络系统在云计算时代变得越来越重要了。从 2008 年到 2014 年,谷歌自家的总服务器的通讯率比以往增加了 50 倍。为什么增长速度如此之快呢?谷歌自己总结了如下几点:
数据的大小在不断增加网络服务需要更多的数据应用之间需要互相分享数据;比如,网页搜索和服务商广告正所谓“得网络者得天下”,谷歌越来越重视在数据中心里面网络的性能。但是研究人员发现,当时市面上的交换器(Switches)的目标并不是数据中心市场,所以并没有为数据中心进行专业的优化。虽然当时的交换器支持很多通讯协议,但它们对数据中心并没有很明显的帮助。其次,如果一个交换器性能降低或者下线,那么会对很多数据中心的应用造成严重的影响。
当时谷歌使用的是一种简易的网络集群架构,名叫 “Four-Post Cluster Architecture"(图2)。 从图中可以看出,集群路由器拥有 512 个 1G 带宽的接口,连接到了每个机架顶部 (ToR, Top of Rack)。每个机架(Rack)可以装载 40 个服务器,所以整个集群可以达到 40*512=20k 个服务器。
这种架构的优点就是搭建特别简单,但是缺点也非常的明显:
可扩展性很差 —— 一旦整个集群需要添加服务器或者额外的机架,需要添加新的路由器,并且每个路由器都需要连入新的机架如果需要充分发挥路由器的 512 个接口的性能,需要很多机架和服务器才行大带宽的应用(High-BandWidth App)需要装载在一整个机架(Rack)里面才能避免用量过载(Oversubscription)所以,谷歌秉着 “没有人做就我来做” 的精神,打算自己设计一套针对数据中心优化的网络架构。他们的设计原则如下:
使用 Clos Topologies。在电信领域,Clos 网络是一种多级电路交换网络,它代表了理想化的多级交换系统(来自 Wikipedia)。这种形式的网络好处就是:理论上,通过添加多个层级,它的大小可以任意改变。但是整体网络的大小取决于软件控制面(Control Plane)的能力,并且光纤的扇出(Fanout)也是一大挑战。使用商业芯片(Merchant Silicon)。谷歌决定使用市面上已有的以太网交换器芯片(Ethernet Switch)来设计网络。这些芯片通常都是有着通用的用途(General-Purposed),并且稳定的价格。使用中心化的控制协议(Control Protocols)。由于使用了 Clos 网络,软件的控制变得复杂的多,所以中心化的控制协议能够很有效的减少复杂度。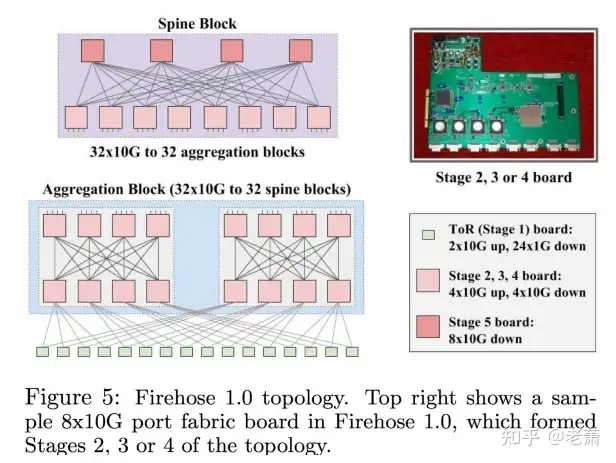
谷歌的第一代网络架构名叫 Firehose 1.0。第一代的目标是使用具有双通道带宽的 1Gbps 交换器芯片(Bisection BandWidth)来为 10K 服务器提供网络服务。
图3 右上角展示了一块可以集成网络层级 2、3、4 的电路板。四个交换芯片和服务器可以通过板子上的 PCI-e 接口连接在一起。但是这样做会有许多问题:
重启时间非常的长如果负责路由任务的服务器下线(offline)的话,那么整个机架都不能正常工作不仅如此,这一代最大的问题就是不可靠性 ——如果一个 ToR 的上行线路(Uplink)不工作了,那么它与它成对的机架之间就完全失联了。
由于复杂的连线、严重的不可靠性、还有上面复杂棘手的问题,Firehose 1.0 并没有正式投入使用,但是给之后的设计带来经验以及新思路。

第二代架构叫做 Firehose 1.1,是来上一代 Firehose 1.0 的改进版本。在这一版本中,有许多新特性和新硬件加入进来。图4 的左上角是一个新硬件名叫 线卡(Linecard),右上角展示了一个由 6 个线卡组成的底盘(Chassis),底盘中使用了 单板计算机(Single-Board Computer, SBC)来通过 PCI 控制每个线卡(Linecard)。
由于使用了新一代的交换芯片(Switch),接口的数量直接翻倍,这也使得 Firehose 1.1 有了新的架构。得益于多出的两个接口,两个 ToR 会直接连接在一起,这样使得整体的过载率(Oversubscription Rate)不超过 2 : 1。
在软件方面,设计人员建造了一个控制面板(Control Plane)来配置并且管理单板机(SBC)。

当然 Firehose 1.1 也存在这问题和挑战。最大的问题就是服务器之间的连线问题。图5 展示了 Firehose 1.1 每个机架的的样子。从图中可以看到,每个机架(Rack)由 3 个底盘(Chassis)构成,并且使用当时的一种名叫 CX4 的铜线连接。CX4 铜线的最大长度是 14 米,但当时有的连接处已然超过了 CX4 的最大长度。谷歌想出的解决方案是使用长度更长的光纤来代替铜线,比如,他们最后使用的 EOE 光纤就可以长达 100 米。
解决完了连线问题,最终 Firehose 1.1 在谷歌内部投入了使用,带来了很多的好评。

相比于之前的 Firehose 1.1,谷歌的第三代网络 Watchtower 最大的更新点在于使用了新的 16x10G 的交换芯片,比上一代的接口数量提高了两倍。每个底盘(Chassis)更是新增了两个线卡(Linecard)的插槽,所以底盘提高到了 128x10G。
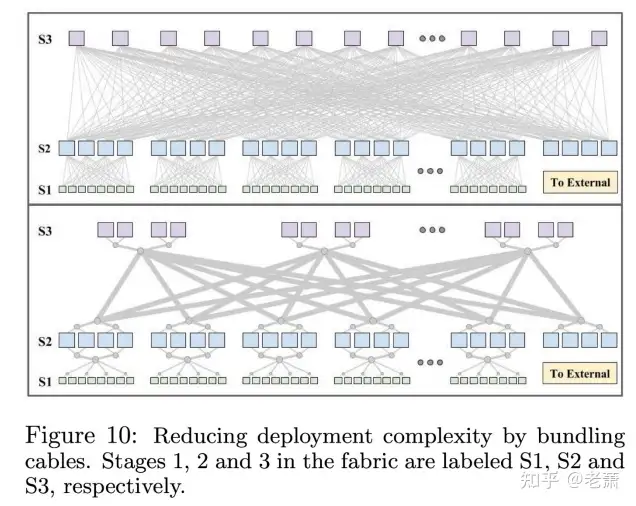
并且,相较于前一代的连接线,这一代有了新的改动。为了减少安装时的复杂度,谷歌已经在线卡中将各个需要服务器和交换芯片连接好了,外部的将密密麻麻的网络连接线也打包在一起,这样大大减少了杂乱的网线,也减少了错误发送的几率。
但这样设计的网络架构,有一个缺点,就是非常费钱,并且不是所有的应用都需要如此大的网络带宽。为此,谷歌提出了一种解决方法 —— 一开始只安置 50% 数量的服务器以及网络设备,当带宽的需求增加时,逐渐增加到 100%。这种解决方法可以有两种方案:(图8)
一开始只安置一半的 S2 交换器(Stage 2)(Figure 11 A)一开始只安置一半的 S3 交换器(Stage 3)(Figure 11 B)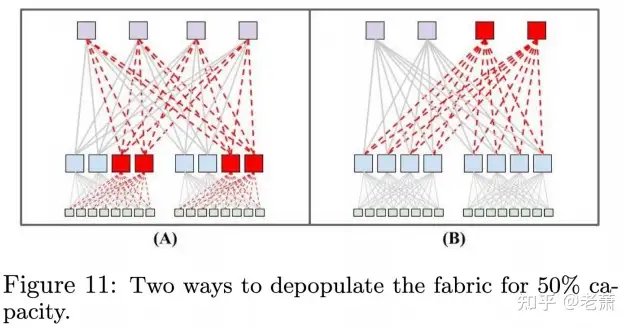
第一种方案的好处是:可以最大化的节约开支。第二种的好处是:虽然前期成本较大,但相比于第一种,每个 ToR 的带宽比第一种方案大了两倍。
最终,这一代(Watchtower)以及下一代(Saturn)的网络架构选择了第一种解决方案,而后面的 Jupiter 架构,选择了 Plan B
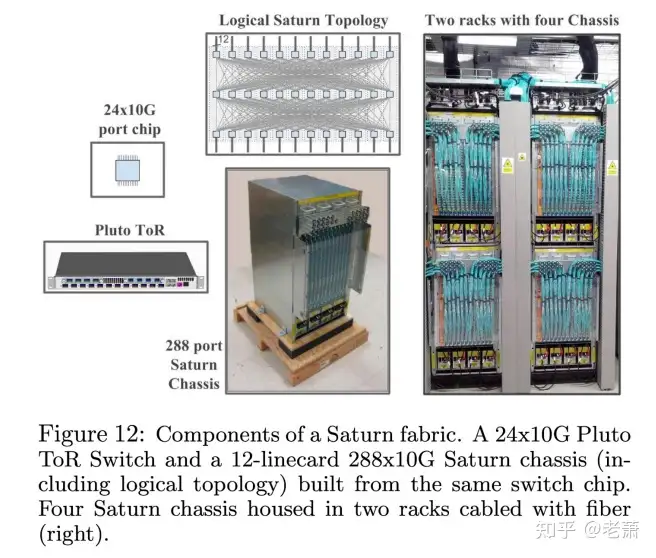
第四代 Saturn 架构的诞生是为了迎合日益增长的服务器数量和带宽需求。这一代也选择了当时市场上新的 ToR 硬件 —— 有着 24 个 10G 接口的 Pluto ToR。底盘(Chassis)也重新设计,可以使其容纳 12 个线卡(Linecards),最高可以达到 288x10G。
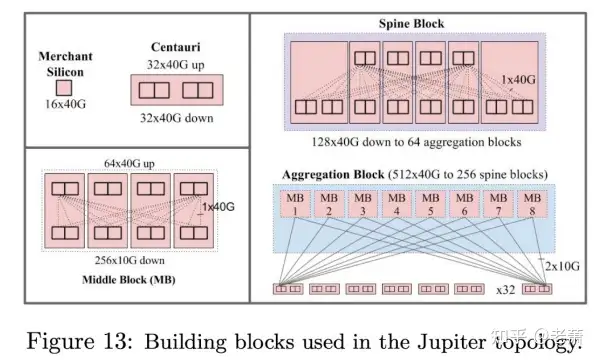
论文作者在选题时选用 Jupiter Rising 还是有原因的,因为第五代架构最大的特点,就是使数据中心集群内部的 Clos 网络在带宽上统一化,这样一来软件就不需要考虑网络架构上的事情,从而屏蔽了底层的一些细节。谷歌对商业芯片的选择也发展到了 16x40G,并且在 Jupiter 网络里,谷歌设计了新的底盘,名为 Centauri Chassis,里面集成了四个交换芯片,图10 的左上角就展示了 Centauri 的结构图,并且这一代的 ToR 就由 Centauri Chassis 进行不同的配置而实现(48x10G 的下行服务器连接,16x10G 的上行连接)。
谷歌也在这一代设计新的网络模块 —— Middle Block (MB)。Middle Block 是由四个 Centauri Chassis 组合而成,多个 Middle Block 也被实现在 Aggregation Block 中。
虽然 Jupiter 进步很多,但同时也引发了新的问题和挑战:
因为带宽一致,所以整体网络对如何应对错误也是一大挑战在 Jupiter 诞生的时候,也正值各大数据中心厂商尝试使用异构计算的时候,如何让数据中心网络支持异构的硬件(比如 TPU、GPU、FPGA 等等)将是下一代优化的重点这篇论文很长,上半部分关于五代架构发展就分享到这里了,下篇将会讲述由于网络架构的改变,软件使如何优化以及管理的。
老萧过往文章:
欢迎关注我的专栏:老萧追芯,和老萧一起学习芯片行业的点点滴滴
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图