
原标题:腾讯云首次披露自研星脉高性能计算网络
AIGC的爆发除了带来算力上的挑战,对网络的要求也达到了前所未有的高度。6月26日,腾讯云首次对外完整披露自研星脉高性能计算网络:星脉网络具备业界最高的3.2T通信带宽,能提升40%的GPU利用率,节省30%~60%的模型训练成本,为AI大模型带来10倍通信性能提升。基于腾讯云新一代算力集群HCC,可支持10万卡的超大计算规模。
AIGC的火爆带来AI大模型参数量从亿级到万亿级的飙升。为支撑海量数据的大规模训练,大量服务器通过高速网络组成算力集群,互联互通,共同完成训练任务。
大集群不等于大算力,相反,GPU集群越大,产生的额外通信损耗越多。大带宽、高利用率、信息无损,是AI大模型时代网络面临的核心挑战。
千亿、万亿参数规模的大模型,训练过程中通信占比最大可达50%,传统低速网络的带宽远远无法支撑。同时,传统网络协议容易导致网络拥塞、高延时和丢包,而仅0.1%的网络丢包就可能导致50%的算力损失,最终造成算力资源的严重浪费。
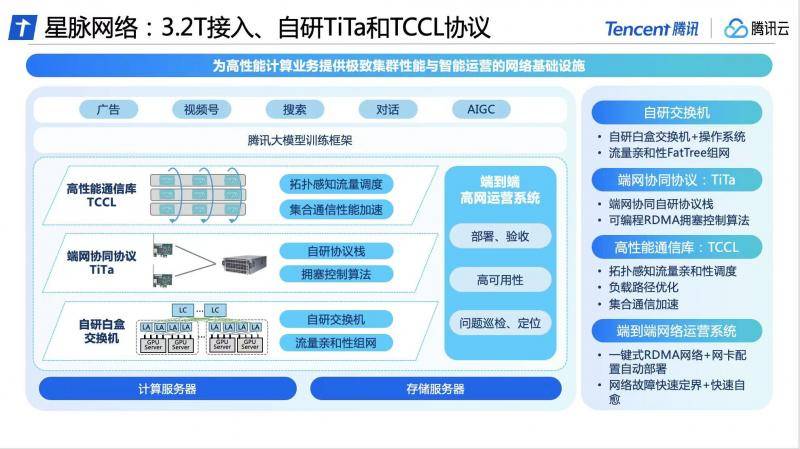
基于全面自研能力,腾讯云在交换机、通信协议、通信库以及运营系统等方面,进行了软硬一体的升级和创新,率先推出业界领先的大模型专属高性能网络——星脉网络。
在硬件方面,星脉网络基于腾讯的网络研发平台,采用全自研设备构建互联底座,实现自动化部署和配置。
在软件方面,腾讯云自研的TiTa网络协议,采用先进的拥塞控制和管理技术,能够实时监测并调整网络拥塞,满足大量服务器节点之间的通信需求,确保数据交换流畅、延时低,实现高负载下的零丢包,使集群通信效率达90%以上。
此外,腾讯云还为星脉网络设计了高性能集合通信库TCCL,融入定制化解决方案,使系统实现了微秒级感知网络质量。结合动态调度机制合理分配通信通道,可以避免因网络问题导致的训练中断等问题,让通信时延降低40%。
网络的可用性,也决定了整个集群的计算稳定性。为确保星脉网络的高可用,腾讯云自研了端到端的全栈网络运营系统,通过端网立体化监控与智能定位系统,将端网问题自动定界分析,让整体故障的排查时间由天级降低至分钟级。同时,大模型训练系统的整体部署时间从19天缩减至4.5天。
文/北京青年报记者 温婧
编辑/樊宏伟返回搜狐,查看更多
责任编辑:
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



