
打开一篇篇 IT 技术文章,你总能够看到“大规模”、“海量请求”这些字眼。如今,这些功能强大的互联网应用,都运行在大规模数据中心上,然而,对于大规模数据中心,你又了解多少呢?实际上,除了阅读一些科技文章之外,你很难得到更多关于数据中心的信息。数据中心每个机器的运行情况如何?这些机器上运行着什么样的应用?这些应用有有什么特点?对于这些问题,除了少数资深从业者之外,普通学生和企业的研究者很难了解其中细节。
2015 年,我们尝试在阿里巴巴的数据中心,将延迟不敏感的批量离线计算任务和延迟敏感的在线服务部署到同一批机器上运行,让在线服务用不完的资源充分被离线使用以提高机器的整体利用率。经过 3 年多的试验论证、架构调整和资源隔离优化,目前这个方案已经走向大规模生产。我们通过混部技术将集群平均资源利用率从 10% 大幅度提高到 45%。另外,通过各种优化手段,可以让更多任务运行在数据中心,将“双11”平均每万笔交易成本下降了 17%,等等。

那么,实施了一系列优化手段之后的计算机集群究竟是什么样子?混部的情况究竟如何?除了文字性的介绍,直接发布数据能够更加拉近我们与学术研究、业界同行之间的距离。为了让有兴趣的学生以及相关研究人员,可以从数据上更加深入地理解大规模数据中心,我们特别发布了这份数据集。数据集中记录了某个生产集群中服务器以及运行任务的详细情况。在数据集中,你可以详细了解到我们是如何通过混部把资源利用率提高到 45%;我们每天到底运行了多少任务;以及业务的资源需求有什么特点,等等。如何使用这份数据集,完全取决于你的需要。
刚刚发布的 Alibaba Cluster Data V2018 包含 6 个文件,压缩后大小近 50GB(压缩前 270+GB),里面包含了 4000 台服务器、相应的在线应用容器和离线计算任务长达 8 天的运行情况,具体信息你可以在 GitHub 中找到。
通过这份数据,你可以:
了解当代先进数据中心的服务器以及任务运行特点;试验你的调度、运筹等各种任务管理和集群优化方面的各种算法并撰写论文;利用这份数据学习如何进行数据分析,揭示更多我们自己都未曾发现的规律。只看上面这几点,没有接触过类似数据的朋友,可能对于这份数据的用处还是没有概念,下面我举几个简单的例子:
电商业务在白天和晚上面临的压力不同,我们如何在业务存在波峰波谷的情况下提高整体资源利用率?你知道我们最长的 DAG 有多少依赖吗?一个典型的容器存在时间是多久?一个计算型任务的典型存在时间是多少?一个 Task 的多个 Instance 理论上彼此很相似,但是它们运行的时间都一样吗?实际上,学者们甚至可以用这些数据作出更加精彩地分析。
2017年,我们曾开放的第一波数据(Alibaba Cluster Data V2017),已经产生了多篇优秀的学术成果。以下是学者们在论文中引用数据(Alibaba Cluster Data V2017)的例子,其中不乏被 OSDI 这样顶级学术会议收录的优秀文章。我们期待,未来你也能与我们共同分享你用这份数据产生的成果!
"LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation, Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang, Purdue University. OSDI18" (Best paper award!)
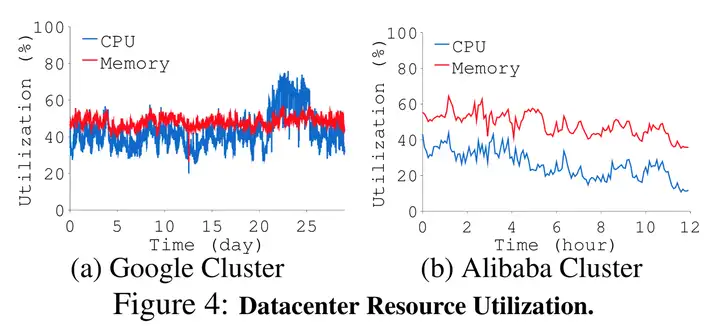
"Imbalance in the Cloud: an Analysis on Alibaba Cluster Trace, Chengzhi Lu et al. BIGDATA 2017"
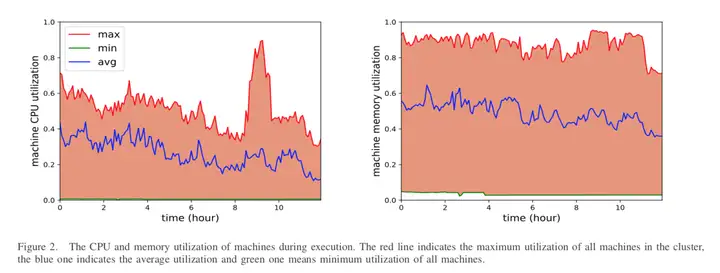
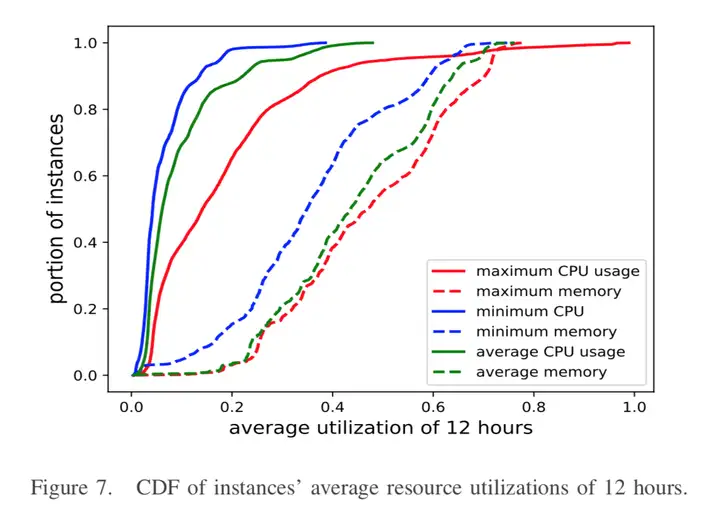
"CharacterizingCo-located Datacenter Workloads: An Alibaba Case Study, Yue Cheng, Zheng Chai,Ali Anwar. APSys2018"
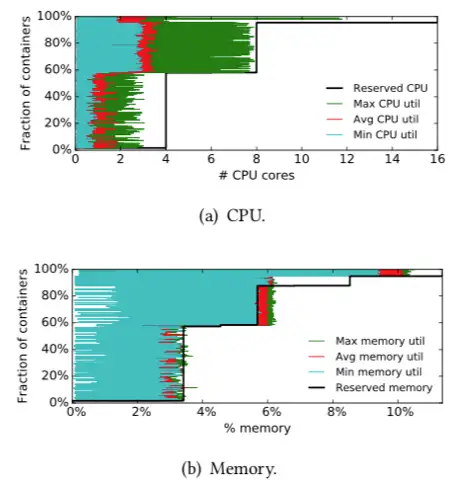
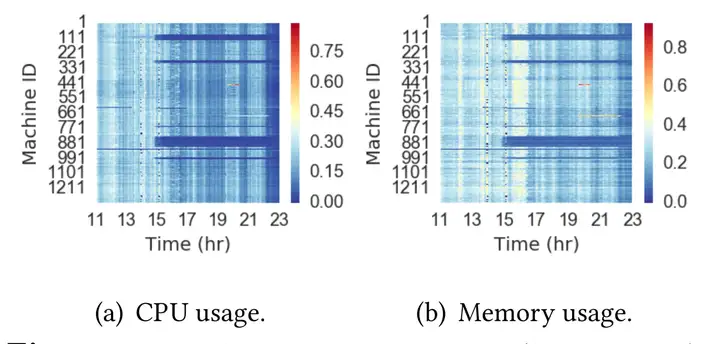
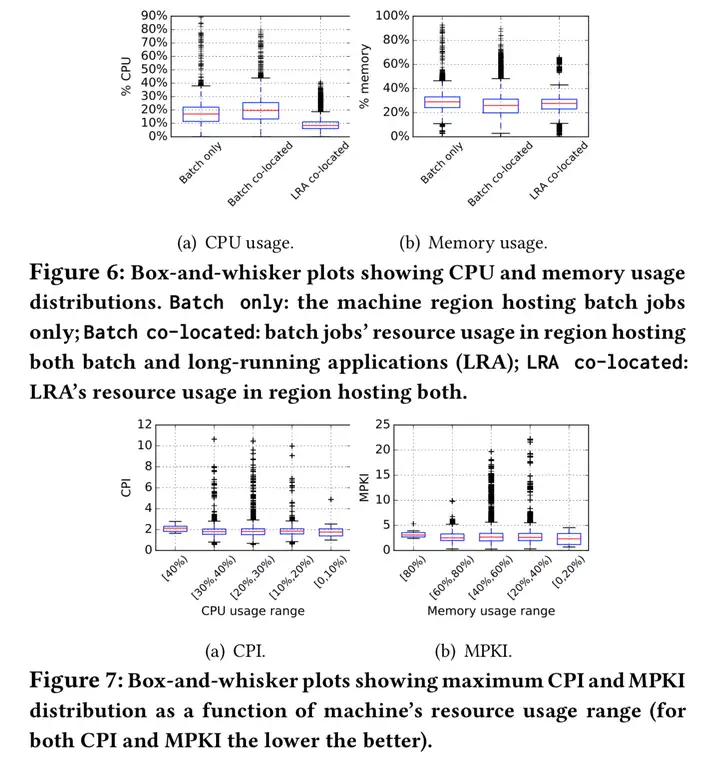
"The Elasticity and Plasticity in Semi-Containerized Co-locating Cloud Workload: aView from Alibaba Trace, Qixiao Liu and Zhibin Yu. SoCC2018"
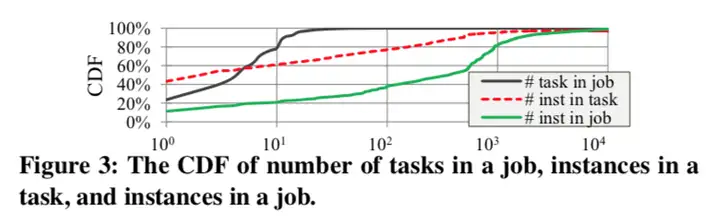


新版本 V2018 与 V2017 存在两个最大的区别:
我们加入了离线任务的 DAG 任务信息,据了解,这是目前来自实际生产环境最大的 DAG 数据。
什么是 DAG?
离线计算任务,例如 Map Reduce、Hadoop、Spark、Flink 中常用的任务,都是以有向无环图(Directed Acyclic Graph,DAG)的形式进行编排的,其中涉及到任务之间的并行、依赖等方面。下面是一个 DAG 的例子。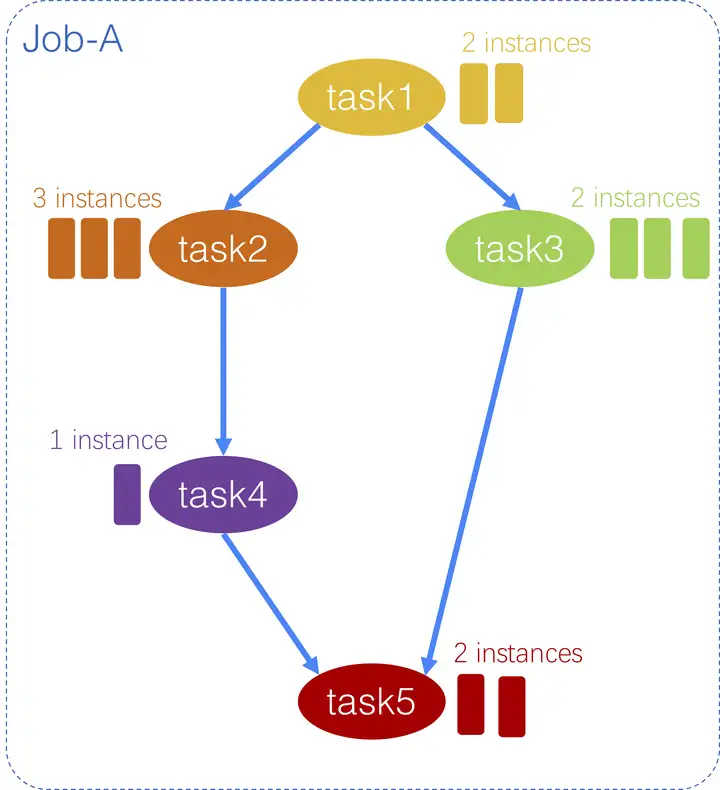
上一版数据包含了约 1300 台机器在约 24 小时的内容数据,而新版 Cluster Data V2018 中包括了 4000 台机器 8 天的数据。
本文作者:jessie筱姜
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
本文为云栖社区原创内容,未经允许不得转载。
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



