
万物互联的时代,核心是算力的分配。以后的电子产品,可能都会像用电器上面一样标上“算力功率”,每个电子产品需要消耗多少计算资源-算力,当然多半咱们以后得像买水买电一样,也去买算力,哈哈哈哈哈。当然,算力可能是万物互联时代的资源的衡量,对于电子产品的智能化会有什么智能指标?我觉得算力目前来看是衡量不了的,用人衡量?“半人”智慧的计算机,“三人”智能的家庭管家,0.5人的智能,哈哈哈哈,听起来怪瘆人的。以自己为智能衡量?哈哈哈0.5狼。
随着当前人工智能技术的不断发展,智能社会也被更多地提及,虽然当前很多关于智能社会的描述和理解都存在一定的局限性,但是不可否认的是,智能社会正在逐渐向我们走来。随着5G通信的落地应用,以及人工智能平台开放,未来人工智能技术将广泛应用在生产和生活的诸多场景下,大量的智能体将重塑整个产业领域的生产、运营和管理模式[1]。
今天,数字技术开始深入生产生活的每一环节。然而要推动数字产业的高水平发展,首先要确保拥有处理巨量数据的能力。随着数据被列入生产要素,算力已成为重要的生产力。根据IDC发布的《2020全球计算力指数评估报告》,一国的算力指数每提高1个百分点,数字经济和GDP将分别增长3.3‰和1.8‰。
数字经济对算力的需求日益增大,加之新基建的东风,作为算力基础设施的数据中心、超算中心、智能计算中心也迈入加速发展阶段。工信部数据显示,截至2020年底,我国在用的数据中心机架超过400万架,年均增速超30%。
算力"突飞猛进"的同时,市场认知却严重滞后。大多数人仍然对算力相关的概念比较陌生——算力如何衡量?不同算力等级间有何区别?算力与应用场景如何匹配?
首先需要知道算力的计量单位FLOPS(Floating-point operations per second)。
FLOPS表示每秒浮点的运算次数。具体使用时,FLOPS前面还会有一个字母常量,例如TFLOPS、PFLOPS。这个字母T、P代表次数,T代表每秒一万亿次,P代表每秒一千万亿次。
"https://zhuanlan.zhihu.com/p/546927592">爱喝水的大灰狼:地平线旭日X3派-上路-“国产树莓派”配置, 像现在的AI嵌入式的板子,已经可以实现5-10 TFLOPS的算力需求的模型部署了。除了运算次数,衡量算力水平时还要看算力精度。例如,1000FLOPS的AI计算中心所提供的的算力,与1000FLOPS超级计算机提供的算力,虽然数值相同,但由于精度不同,实际算力水平也是天壤之别。
根据参与运算数据精度的不同,可把算力分为双精度算力(64位,FP64)、单精度算力(32位,FP32)、半精度算力(16位,FP16)及整型算力(INT8、INT4)。数字位数越高,意味着精度越高,能够支持的运算复杂程度就越高,适配的应用场景也就越广。
超级计算机常被用于需要大量运算的工作,譬如天气预报、运算化学、分子模型、天体物理模拟等,是为高精尖科学领域提供极致算力的服务。由于这类科学领域的计算对数据精度要求高,因此通常的超算系统以双精度数值计算为主。
近年来,AI在国内获得快速发展,为匹配AI训练与推理的特殊需求,AI超算系统应运而生。不同于传统超算,AI超算系统大多用于语音、图片或视频的处理,浮点计算下的低精度计算甚至整型计算即可满足相应需求。
要确定不同精度算力的性能,需通过各自领域内的专用测试程序来测试。例如,用于测试超级计算机性能的Linpack测试专注于双精度算力;用于智能计算机性能的Resnet-50则专注于半精度算力。
如果将参与运算的数据比作货物,那么双精度算力就可以看作重型卡车,低精度算力可以看作是小型货车。重型卡车也可以承担小型货车的任务,但功耗过高,会造成浪费。而小型货车由于自身性能限制,无法承担重型卡车的任务。
同样,超级计算机的双精度算力即可以看作是重型卡车,是一种"通用算力",可以承担各种计算任务;
而单精度、低精度算力作为小型货车,则是一种"专用算力",是专门为AI的训练和推理设计,无法承担超级计算机的计算任务[2]。
算力网络从传统云网融合的角度出发,结合边缘计算、雾计算、网络云化以及智能控制的优势,通过网络连接实现更加广泛的算力资源的纳管和动态调度。
但是,区别于传统的云计算资源的纳管采用集中式的资源管理或者集约化的资源提供,在算力网络的资源纳管中更多考虑了网络延时、网络损耗对于资源调度方面的影响[3]。
因此网络的核心价值是提高效率,算力网络的出现正是为了提高端、边、云三级计算的协同工作效率。

随着越来越多数据的产生以及更加强大的算力算法的运用,物联网应用也变得越来越智能。典型的物联网应用也从简单的数据感知、收集和表示转向复杂的信息提取和分析。
未来,物联网可广泛应用于环境监测、城市管理、医疗健康等任务。这些任务往往需要实时的数据处理、信息提取和分析决策。
但是,由于有限的通信带宽、不稳定的网络连接以及严格的时延要求等,仅仅依靠云计算已无法支持无处不在且日渐强大的物联网部署和应用。为应对这一挑战,多层次算力网络被提了出来[4]。
目前,主流计算技术主要有云计算(CloudComputing)、雾计算(FogComputing)和边缘计算(EdgeComputing)。
那么何谓云计算、雾计算、边缘计算?以及他们之间有何区别?各自具备何种优势?
(1)为什么需要“云”?
传统的应用正在变得越来越复杂:需要支持更多的用户,需要更强的计算能力,需要更加稳定安全等等,而为了支撑这些不断增长的需求,企业不得不去购买各类硬件设备(服务器,存储,带宽等等)和软件(数据库,中间件等等),另外还需要组建一个完整的运维团队来支持这些设备或软件的正常运作,这些维护工作就包括安装、配置、测试、运行、升级以及保证系统的安全等。
便会发现支持这些应用的开销变得非常巨大,而且它们的费用会随着你应用的数量或规模的增加而不断提高[5]。
这也是为什么即使是在那些拥有很出色IT部门的大企业中,那些用户仍在不断抱怨他们所使用的系统难以满足他们的需求。而对于那些中小规模的企业,甚至个人创业者来说,创造软件产品的运维成本就更加难以承受了。
所以,云计算,应运而生——更大、更快、更强。

(2)什么是云计算?
形象点来说,当你需要用一个软件时,你不用跑去电脑城,打开应用商店,它就下载下来了,你只需要交钱就是了;当你想看报纸的时候,你不用跑去报刊亭,只要打开头条新闻,新闻唾手可得;当你想看书的时候,你不用跑去书城,只需要打开阅读软件,找到这样的一本书,在手机上阅读;当你想听音乐的时候,你不用再跑去音像店苦苦找寻CD光碟,打开音乐软件,就能聆听音乐;
云计算,像在每个不同地区开设不同的自来水公司,没有地域限制,优秀的云软件服务商,向世界每个角落提供软件服务——就像天空上的云一样,不论你身处何方,只要你抬头,就能看见!
专业的说,云计算是一种共享计算资源的计算模式,计算资源共享池(包括网络接入、服务器、存储设备、软件、服务)部署在位于互联网中的大型数据中心,提供“云端服务”。
用户按需接入,获取相应的计算资源。通常用于海量数据处理或高强度运算场景。同时,由于在互联网上部署了多个资源池副本,能有效保障系统可靠性和数据安全性。
但是,云计算就是把自己全盘交给厂家,毫无隐私可言,自己的数据安全就全赖厂家了,当然目前来说大家是在互联网上“裸奔”,谁也不差谁。
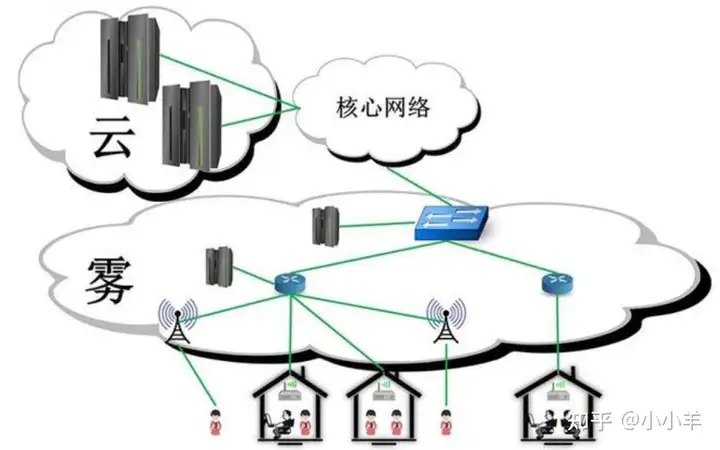
雾计算是介于云计算和个人计算之间的,是半虚拟化的服务计算架构模型,强调数量,不管单个计算节点能力多么弱都要发挥作用,更具备可扩展性。
由性能较弱、更为分散的各种功能计算机组成,迁移云计算中心任务到网络边缘设备执行的一种高度虚拟化计算平台。它通过减少云计算中心和移动用户之间的通信次数,以缓解主干链路的带宽负载和能耗压力[6]。
3.3 边缘计算
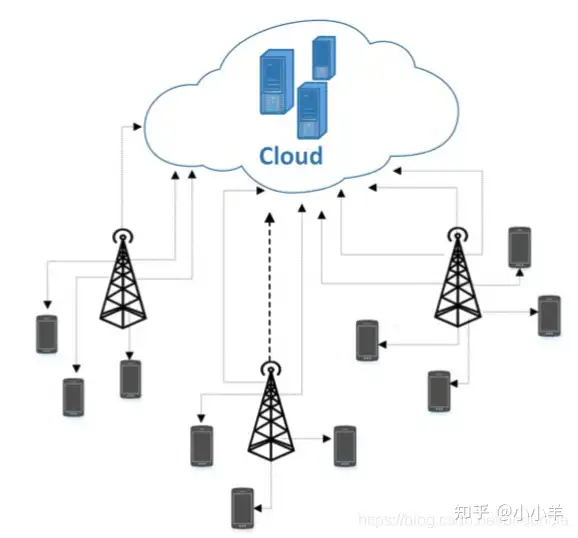
边缘计算的基本理念是将计算任务在接近数据源的计算资源上运行,可以有效减小计算系统的延迟,减少数据传输带宽,缓解云计算中心压力,提高可用性,并能够保护数据安全和隐私。
和传统的中心化思维不同,边缘计算将计算任务在接近数据源的计算资源上运行,其主要计算节点以及应用分布式部署在靠近终端的数据中心,这使得在服务的响应性能、还是可靠性方面都是高于传统中心化的云计算概念。
具体而言,将云服务器上的功能下行至边缘服务器,以减少带宽和时延[6]。
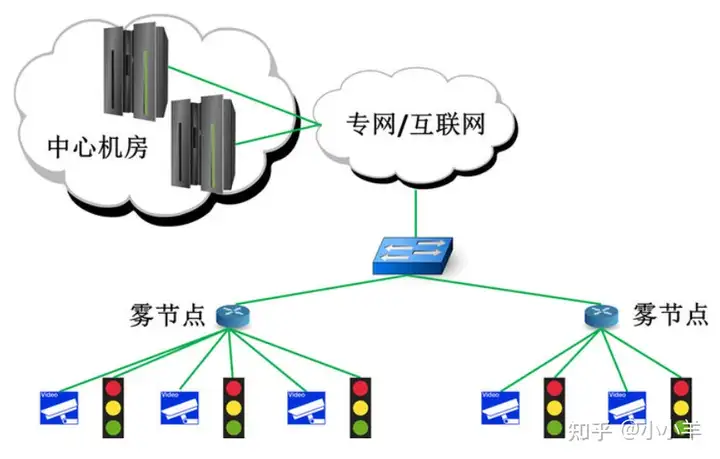
边缘计算是在理清云计算的框架基础上,认真的分析总结云计算具有的实时性不够、带宽不足、能耗较大、不利于数据安全和隐私等问题,边缘计算模型具有几个明显的优点:
①在网络边缘处理大量临时数据,不再全部上传云端,这极大的减轻了网络带宽和数据中心功耗的压力。
②在靠近数据生产者处做数据处理,不需要通过网络请求云计算中心的响应,大大减少了系统延迟,增强了服务响应能力。
③边缘计算将用户隐私数据不再上传,而是存储在网络边缘设备上,减少了网络数据泄露的风险,保护了用户数据安全和隐私。
边缘计算和云计算两者实际上都是处理大数据的计算运行的一种方式,云计算把握整体,边缘计算更专注局部。
边缘计算更准确的说应该是对云计算的一种补充和优化。
边缘计算具体指代云和设备的边界,雾计算而言因为和云相比位置上更接近设备,所以表示为雾。
雾计算:
经常是在IoT背景下被提及到,典型的主要业务是路由器、接入点甚至是与传感器和执行器一起的计算设备。处理能力放在包括IoT设备的LAN里面,
这个网络内的IoT网关,或者说是雾节点用于数据收集,处理,存储。多种来源的信息收集到网关里,处理后的数据发送回需要该数据的设备。
雾计算的特点是处理能力强的单个设备接收多个端点来的信息,处理后的信息发回需要的地方,和云计算相比延迟更短。
和边缘计算相比较的话,雾计算更具备可扩展性, 更好实现。雾计算不需要精确划分处理能力的有无,根据设备的能力也可以执行某些受限处理,但是更复杂的处理实施的话需要积极的连接。
边缘计算:
进一步推进了雾计算的“LAN内的处理能力”的理念,处理能力更靠近数据源。不是在中央服务器里整理后实施处理,而是在网络内的各设备实施处理。边缘计算各自的设备独立动作,可以判断什么数据保存在本地,什么数据发到云端[7]。
雾计算和边缘计算具有很大的相似性,但是雾计算关注基础设施之间的通信问题,而边缘计算除了关注基础设施之外,也关注边缘设备,更加强调计算问题。
[3] 李铭轩、曹畅、唐雄燕、何涛、李建飞、刘秋妍.面向算力网络的边缘资源调度解决方案研究[J].数据与计算发展前沿,2020,v.2;No.6(04):84-95.
[4] 刘泽宁,李凯,吴连涛,等.多层次算力网络中代价感知任务调度算法[J].计算机研究与发展,2020(9):1810-1822.
[5] https://blog.csdn.net/weixin_34080571/article/details/91475133[6] https://blog.csdn.net/birduncle/article/details/86023665[7] 陈晨.云计算,雾计算和边缘计算在智慧交通中的应用[J].数字通信世界,2019(9).相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



