
世界上最大和人气最高的数据库是哪个, Access数据库到底排在多少位呢?Access排名不降反升!
国产的Oceanbase TiDB数据库 TDSQL 都不错,但奈何全球数据库排名都是以国外数据为准,中国为什么不弄一个自己的数据库排名?
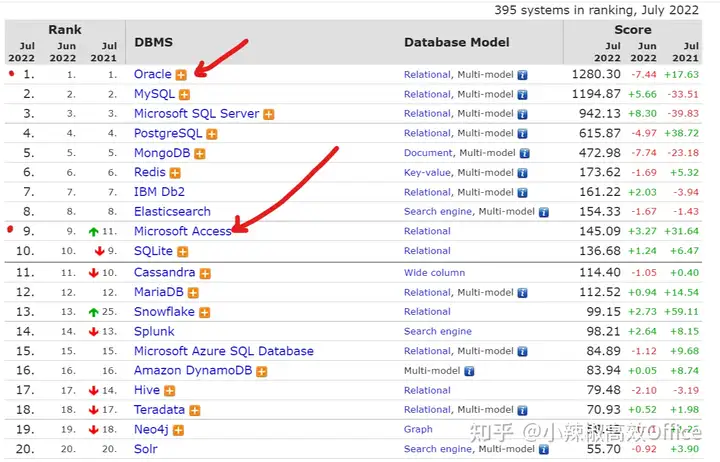
根据数据库网站 DB-Engines 7月最新排名显示,排在第1位的,还是ORACLE数据库,而Access数据库排在所有数据库的第9位,排在关系数据库的第6位。排名还是非常高的。
DB-Engines Ranking 根据数据库管理系统的受欢迎程度对它们进行排名。该排行榜是按搜索、谷歌趋势、 Stack Overflow 网站、LinkedIn、Twitter 等社交网络中的关注度, 综合比较进行的排名。该排名涵盖全球 388个数据库系统,排名每月更新一次。
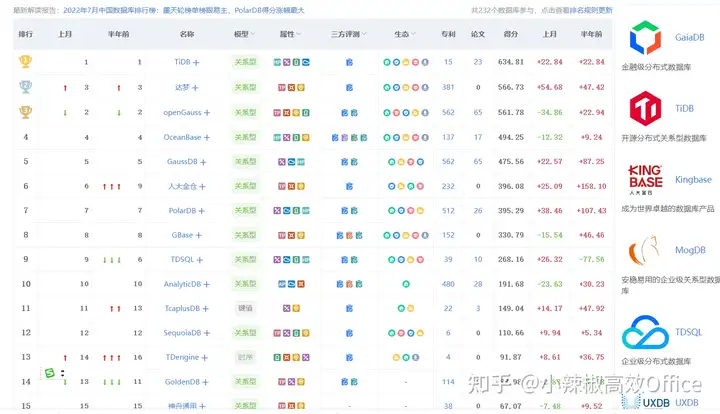
再补充下国产数据库的排名
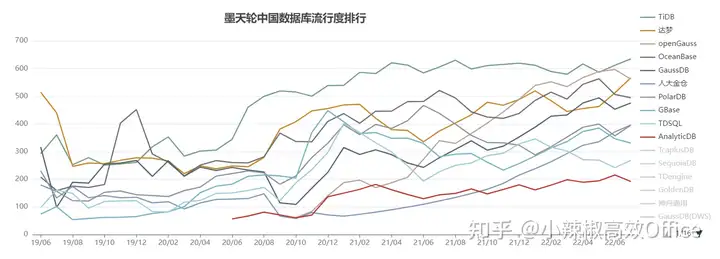
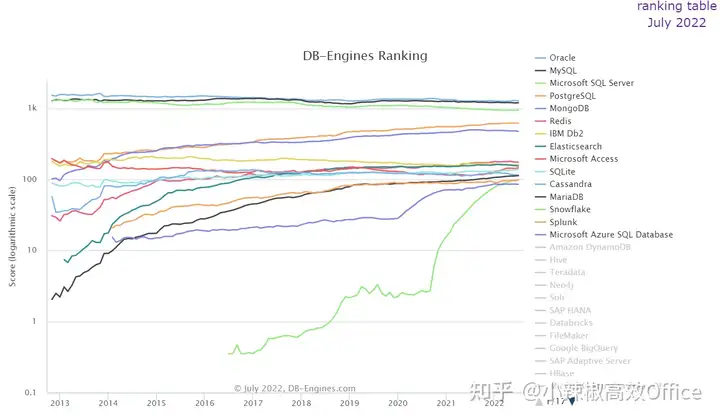
从上面排名图中我们发现
这么多年,虽然Oracle数据库被其它数据库不断蚕食,还瘦死的骆驼比马大,依然排在第一位。
在2022年7月,甲骨文(Oracle)以1280.30的分数,排名第一,但其得分较上月下降了7.74分。
甲骨文旗下的开源数据库MySQL位列第二,微软的SQL Server排名第三。另一个开源数据库PostgreSQL排名第四,它也是前几月流行度上升最快的数据库,但7月得分稍有下降。而第二名MySQL本月比上月稍有上升。
我常用的Mysql SqlServer都在前三甲。
虽然各种声音不断宣告Access在走下坡路,已经快要淘汰,没有人使用它了,但数据说明一切,Access数据一直都在前10名左右,虽然无法回到2012当年最风光的时刻,但今年还从去年同期的11位还爬到了第9位,不降反升。足以说明一切,我用Access, 我骄傲!
Access在6月,7月均有上升,而且上升还有些猛。
在这份排行榜上,部分国产数据库如创业公司PingCAP的TiDB数据库 ,Apache Kylin 涛思数据的TDengine 腾讯云的TDSQL 巨杉数据库的SequoiaDB 人大金仓的KingBase 易鲸捷的EsgynDB 均榜上有名
阿里云有七个数据库上榜,分别是MaxCompute ,AnalyticDB ,ApsaraDB ,Log Service ,AnalyticDB ,Table Store ,TSDB 也榜上有名。不过国产数据库大多在200名以外,不过,DB-Engines是根据国外网站进行的流行度计分,并不能真正反映中国数据库的情况。 国产数据库可看看国产数据库排名表。
以下内容主要摘自:花开半夏
结构化与非结构化数据
简单而言,可以用二维表来表示的就是结构化数据(如,包含有不同字段的一条记录);
相反,不方便用二维逻辑表来表现的数据,如文本、图片、视频、XML、HTML、图像和音频就是非结构化数据。此外,字段可根据需要扩充,即字段数目不定的,可称为半结构化数据。
关系型数据库就是由二维表及其之间的联系所组成的一个数据集。
可以这样理解
1、如果数据集(数据库)是关系型,那么数据一定是结构化的
2、相反如果数据是结构化,那么组成的数据集可能是关系型。
3、关系型数据库的最大特点就是事务的一致性。
传统的关系型数据库读写操作都是事务的,具有ACID的特点,如银行系统 保险系统。但在互联网应用中,一致性却不是显得那么重要。两个人看到同一好友的数据更新的时间差几秒是可以容忍的。
因此,关系型数据库的最大特点在互联网时代已经不那么重要了。
根据早期的数据库理论,常见的数据库模型有三种:分层数据库、网格数据库和关系数据库。 在当今互联网中,最常见的数据库模型主要有两种: SQL关系数据库和NoSQL非关系数据库。
关系数据库前十名包括:
1)关系型数据库的由来
数据库发展的早期,几乎都是集中式的关系型数据库的天下,如商业型数据库ORACLE、SQL Server、IBM DB2、Sybase等,尤其是ORACLE,几乎占到了大型数据库大部分市场份额的70%以上,这也是为什么“去IOE”(IBM的小型机、Oracle的数据库、EMC的存储)工作中去O最难的原因。
后来发展起来的开源数据库有MySQL、PostgreSQL。MySQL使用用户群非常广 ,但也是甲骨文的旗下产品,互联网行业大厂如谷歌、FaceBook、阿里、腾讯、京东 及国内电信 银行、联通、移动等国资企业,都有大规模应用MySQL。PostgreSQL主要在GIS领域处于优势地位,有丰富的GIS数据类型和处理算法。
网格数据库和层次数据库很好地解决了数据集中和共享的问题,但数据库的独立性和抽象水平存在很大缺点。 如果用户访问两个数据库,则必须明确数据的存储结构并指示访问路径。 关系数据库可以很好地解决这些问题。
2)关系型数据库介绍
关系数据库模型将复杂的数据结构组合为简单的二元关系,即二维表格式。 在关系数据库中,对数据的大多数操作都构建在一个或多个关系表中,通过分类、联接、连接或选择这些相关表等操作来管理数据库。
关系数据库问世40多年来,从理论诞生发展到现实产品,如甲骨文和MySQL,甲骨文在数据库领域称霸,形成了一个年达数百亿美元的巨大产业市场。
传统关系数据库: Oracle、MySQL、Microsoft SQL Server、PostgreSQL
大数据常规数据库: Hive、Impala、Presto、ClickHouse
1)非关系型数据库诞生背景
NoSQL是指非关系数据库。 随着互联网web2.0网站的兴起,传统的关系数据库在应对web2.0网站,特别是超大规模、高并发的SNS类型web2.0纯动态网站方面力不从心(小辣椒高效Office),暴露出许多难以克服的问题,但非关系数据库NoSql数据库的效率和性能在某些情况下难以想象,是传统关系数据库的有效补充。
早就有人指出,noSQL(noSQL=notonlySQL )是一场新的数据库革命运动,“不仅仅是SQL”,到了2009年趋势会越来越高。 NoSQL的cjdxf们提倡利用非关系型数据存储,对于利用关系数据库这一铺天盖地的应用,这一概念无疑是一种新的思维方式。 它些数据库大部分都是开源的,可谓百花齐放百家争鸣,常见的产品很多。
2)非关系型数据库种类
(1)键值(Key-Value)存储数据库
键值数据库类似于传统语言中使用的哈希表。 可以使用key添加、查询或删除数据库。 使用key主键进行访问,可以获得高性能和可扩展性。
键值数据库主要使用哈希表。 此表有特定的键和指针,指向特定的数据。 Key/value机型对IT系统的好处是简单、易于部署和高度并发。
典型产品: Memcached、Redis、Ehcache
(2)列存储(Column-oriented)数据库
列存储数据库将数据存储在列族中。 一个列族存储经常一起查询的相关数据,例如人。 我们经常查询某人的名字和年龄,而不是工资。 在这种情况下,姓名和年龄放在一个列族中,工资放在另一列族中。
此类数据库通常用于支持分布式存储的大容量数据。
典型产品: cassandra(AP )、hbase () CP ) ) )。
(3)面向文档(Document-Oriented)数据库
文档类型数据库的灵感来自Lotus Notes办公室软件,与第一个键值数据库相似。 这种类型的数据模型是版本化文档,半结构化文档以特定格式存储,如JSON。 文档类型数据库可以视为键值数据库的升级版,并可以在它们之间嵌套键值。 此外,文档类型数据库比键值数据库的查询效率更高。
文档数据库将数据存储为文档。 每个文档都是一个独立的数据单元,是一组数据项的集合。 每天
个数据项都有一个名词与对应值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON或JSONB等多种形式存储。
典型产品:MongoDB、CouchDB
(4)图形数据库
图形数据库允许我们将数据以图的方式存储。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
典型产品:Neo4J、InforGrid
(5)时序数据库
2017年时序数据库忽然火了起来。开年2月Facebook开源了beringei时序数据库;到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。时序数据库作为物联网方向一个非常重要的服务,业界的频频发声,正说明各家企业已经迫不及待的拥抱物联网时代的到来。
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
典型产品:InfluxDB、Prometheus(普罗米修斯)、OpenTSDB(底层基于HBase)
(6)搜索引擎存储
搜索引擎存储:搜索引擎数据库最近比较火的包括Solr和Elasticsearch等。Solr是Apache 的一个开源项目,基于业界大名鼎鼎的java开源搜索引擎Lucene。在过去的十年里,solr发展壮大,拥有广泛的用户群体。solr提供分布式索引、分片、副本集、负载均衡和自动故障转移和恢复功能。如果正确部署,良好管理,solr就能够成为一个高可靠、可扩展和高容错的搜索引擎。
Elasticsearch构建在Apache Lucene库之上,同是开源搜索引擎。Elasticsearch在Solr推出几年后才面世的,通过REST和schema-free的JSON文档提供分布式、多租户全文搜索引擎。并且官方提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript客户端。目前Elasticsearch与Logstash和Kibana配合,部署成日志采集和分析,简称ELK,它们都是开源软件。最近新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash。
典型产品:Elasticsearch、Solr
(7)、新式关系型数据库(NewSQL ):
NewSQL提供与NoSQL系统相同的扩展性能,且保持传统数据库支持的ACID特性。典型代表:SAP HANA,VoltDB,nuoDB,MariaDB,Pivotal
(8)、MPP(Massively Parallel Processing)数据库:
指使用多个SQL数据库节点搭建的数据仓库系统,MPP解决了单个SQL数据库不能存放海量数据的问题。代表产品有Teradata,Vertica,Redshift,Greenplum
DB-Engines Ranking 是一个数据库管理系统排行列表,按其当前受欢迎程度进行排名。我们使用以下参数来衡量系统的受欢迎程度:
网站上系统的提及次数,以搜索引擎查询中的结果数来衡量。目前,我们使用Google和Bing进行此测量。为了只计算相关结果,我们搜索<system name> 以及术语数据库,例如“Oracle”和“database”。对系统的普遍兴趣。 对于此测量,我们使用Google 趋势中的搜索频率。关于系统的技术讨论频率。 我们使用著名的 IT 相关问答网站Stack Overflow和DBA Stack Exchange上(tmtony)相关问题的数量和感兴趣的用户数量。工作机会的数量,其中提到了系统。 我们使用领先的工作搜索引擎Indeed和Simply Hired上的报价数量。专业网络中的配置文件数量,其中提到了系统。 我们使用国际上最流行的专业网络LinkedIn。社交网络中的相关性。我们计算了Twitter推文的数量,其中提到了该系统。我们通过对各个参数进行标准化和平均来计算系统的流行度值(小辣椒高效Office)。这些数学变换以某种方式进行,以便保留各个系统的距离。这意味着,当系统 A 在 DB-Engines Ranking 中的值是系统 B 的两倍时,那么在单个评估标准上进行平均时,它的受欢迎程度是两倍。
为了消除数据源本身数量变化带来的影响,流行度分数始终是一个相对值,只能与其他系统进行比较来解释。
DB-Engines 排名不衡量系统的安装数量,或它们在 IT 系统中的使用。可以预期,由 DB-Engines 排名衡量的系统受欢迎程度的增加(例如在讨论或工作机会中)在系统的相应广泛使用之前某个时间因素。因此,DB-Engines Ranking 可以作为早期指标。
大家都在使用什么喜欢的数据库,可以在评论区留言。或你对此排名有什么异议,也可发表意见!
相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



