
作者:FYH
大数据平台与数据中台的介绍
点击观看吧:https://m.v.qq.com/play.html?vid=k0904fao381
本文主要介绍大数据平台与数据中台的关系,以及市面主流产品的架构、功能与差异。
前述:今年听到最多的,新经济玩不动了,企业喊的要转型,怎么转?上云,做中台;怎么做,进阿里生态。作为阿里,阿里定义的中台战略,及以中台为抓手,拉企业上云,没有产品,企业为什么要上云。战略必定要以产品为支撑,产品必须为战略服务。具体产品体现为计算存储、数据中台、应用平台。作为厂商,大家都把阿里当渠道商,一家大了,必定很难受。但没办法,就他玩的好,跟着做吧,做了,会死;不做,等死,试试吧。

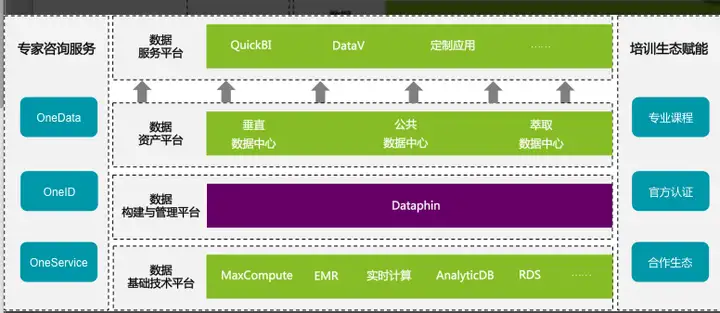
数据中台是数据资产化和价值化体系。它致力于构建既“准”且“快”的“全”“统”“通”的“智能”大数据体系;它在数据赋能业务中形成业务模式,在推进数字化转型中实现价值。部分企业内部将数据中台及其业务模式产品化,提供数据中台智能化解决方案。数据中台由数据资产平台、基础技术平台、数据构建与管理平台、数据服务平台组成。阿里云数据中台解决方案如下图示。
说白了,阿里定义的中台战略,及以中台为抓手,拉企业上云,具体产品体现为计算存储、数据中台、应用平台,其中包括以下内容。
应用平台:经营分析场景QuickBI、营销场景Quick Audience数据中台:数据采集与研发、数据连接与萃取、数据资产管理计算与存储:Maxcompute、Hadoop、EMR。在这里日志做分发的时候用Flink、Blink,做离线计算时使用Maxcompute,QA是做人群标签与人群洞察,QBI抄了BI报表工具,按各家买了的金主的反馈,各个都是眼角含着泪:好不好用,谁用谁知道。

阿里内部的两款大数据开发套件,Datawork与Dataphin,以及市面上的竞对,竞争优势,各有不同。
在实施层面,第一步,先进行服务器的采购,虚拟机的创建。第二步骤,购买大数据开发平台,类似市面上阿里的Dataworks,Dataphin,袋鼠的数栈,数澜的数栖平台。第三步,包括了数据开发、算法开发、数据共享服务开发,在这里,可以引入ISV厂商做实施。第四步,即为数据应用的建设,其中包括了数据分析、可视化大屏、用户画像、标签工厂。往往你告诉客户,数据中台是方法论,客户不认,需要在应用层面找价值,这也是当前在交付层面,遇到阻力比较大的问题,阿里的P8 PPT里的三级火箭、五朵金花、以面找点,以点破面的概念,在客户交付面前,都显得有些苍白无力。

先说对比与结论,在依依展开产品介绍与对比。
一开始大数据开发套件,部分厂商做的相对比较简单,与星环这种独立做计算引擎厂商不同,就是单纯的RD-OS封装Hadoop,Spark。后来进行产品的不断完善,在PaaS层进行开源的深度封装,其中包括了离线计算Spark ,实时计算Flink,产品变得可视化,便捷,具有可操作性。Cloudera是对Hadoop做了封装,各家数据平台厂商在基础上,做封装发行版,封装Hadoop后变成傻瓜式安装。
在产品上来说,Dataworks相对比较成熟,基于阿里自研的Maxcompute计算引擎,也就是原来的ODPS,在完全自主知识产权的基础上,面向项目停供数据平台软硬件服务,当然这个也比较贵,大概在1000w左右。
Dataphin使用了基于阿里自研的Maxcompute计算引擎,同时还带了开源的Hadoop引擎,主打的定位也不一样,在用户不愿选择封住后的Maxcompute,可以选择开源Hadoop,价格不高,大概500w左右,虽然今年阿里主推该产品,但是相对不是很成熟,萃取模块还是有很大的问题。
在部署上,阿里的Maxcompute,Dataworks底座是CDN,硬件是30台-50台,早期甚至是上百台,非常的吃资源,开销非常大。
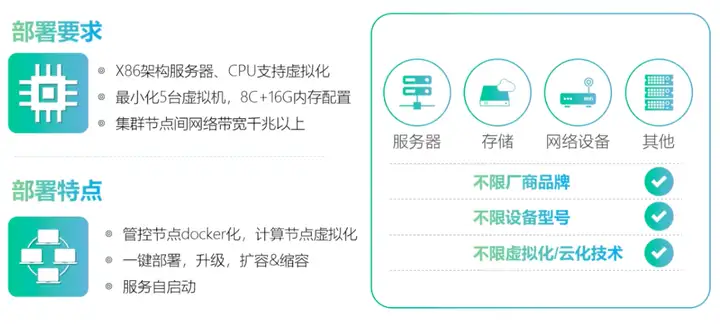
部分厂商,采用服务器的轻部署,不限制服务器、ECS的数量,10台以下,小型机。物理服务器,8核16g。每个企业的数据量,会把5台扩到20台,由于是分布式的,所以扩展起来,也比较方便。
Dataphin是一款集成了阿里巴巴集团OneData理念的产品,定位为智能大数据构建与管理平台,旨在通过提供智能数仓规划、数据引入、数据规范定义、数据建模研发、数据连接萃取、数据资产管理、数据主题式服务的全链路、一站式产品+技术+方法论服务,助力客户高效、优质完成数据中台最核心的大数据建设工作。
在产品层面,Dataphin产品由四部分组成,分别是技术内核、工具层、数据层和管理服务层。
技术内核,一套屏蔽底层计算、存储、软件系统差异的技术框架,保证数据研发可兼容多计算引擎与计算时效,代码自动化生成并实现智能存储与计算,数据服务支持混合存储等。工具层,面向开发者的数据构建与管理的工具,包括基础数据的标准规范及集成引入,公共数据的标准规范定义、智能建模研发、调度运维及机器学习,萃取数据的ID识别连接及标签生产。 数据层,在技术内核基础上,通过工具加工生产,输出三种层次的结构化数据,构建出高保真、面向各业务的基础数据中心,模型化、面向主题的公共数据中心,深度加工、以实体为中心的萃取数据中心。管理及服务层,将数据及数据服务以资产化视角进行管理,以支持数据研发人员及业务人员都可以获取高质量且统一的数据资产;从业务视角将已有数据包装加工为主题式的数据服务,以保障业务可以统一地查询 与调用数据。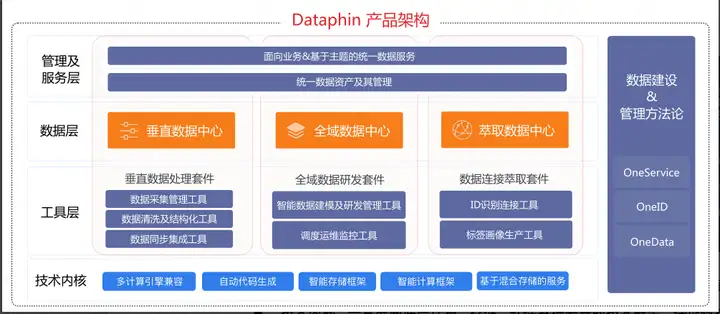
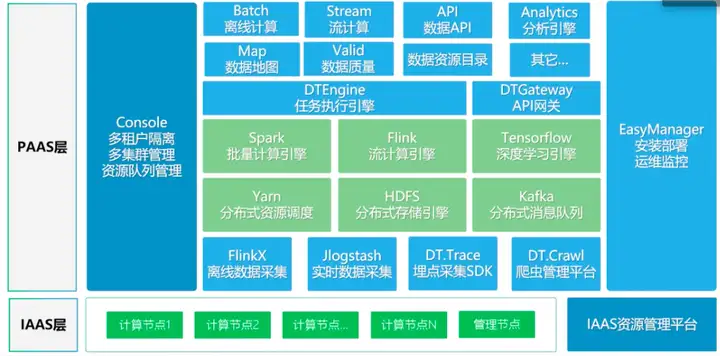
在技术层面上,DataPhin私有化部署技术架构自下而上由五部分组成,分别是存储集群、Mesos调度集群、Master集群、Worker集群和最上层的访问层。
存储集群,从各个业务系统数据源离线采集的业务数据采用阿里云MaxCompute进行存储;DataPhin平台中涉及的所有非结构化数据采用OSS进行存储;Dataphin用户行为审计日志和系统错误日志采用SLS日志服务进行存储;DataPhin平台相关的账号、权限、各种任务配置运行及数据规范定义等元数据采用RDS关系数据库PostgreSQL进行存储;对于DataPhin平台经验使用的账号权限等热点数据采用Redis进行缓存以提升效率。调度集群,采用3个高规格(24C96G)云服务器节点组成,由Apach Mesos分布式资源管理服务和Zookeeper负责分布应用协调服务混布方式组成,Mesos负责整个集群的资源管理和调度,Zookeeper负责应用配置管理和一致性同步。Master集群,采用由规格为4C8G的云服务其部署组成3节点的Master控制集群。Worker集群,采用由规格为12C48G的云服务器部署组成多节点的Worker工作集群,负责DataPhin任务的执行。访问层,采用阿里云SLB负载均衡和DNS服务,作为Dataphin平台的统一访问入口。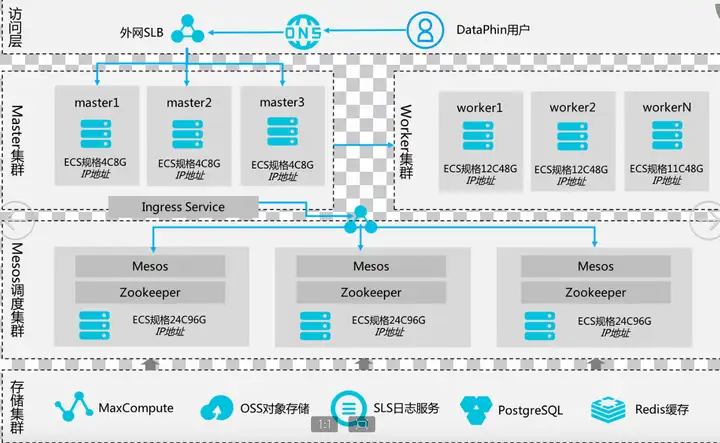
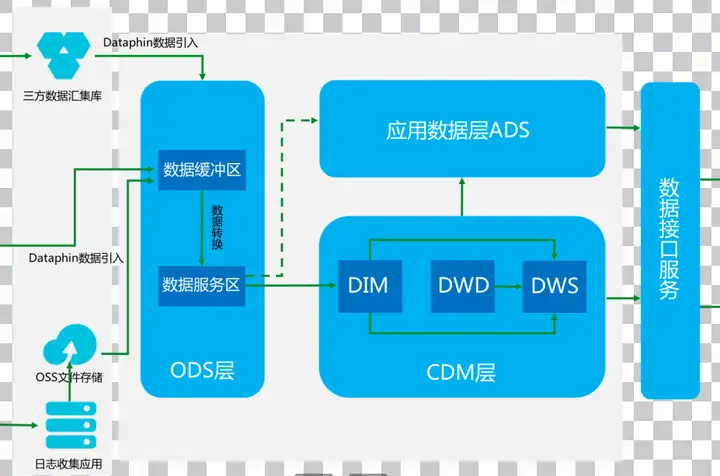
在数据进入数据中台ODS层的数据缓冲区后,针对每天全量同步或每天增量同步的数据在进入ODS层的数据服务区时,针对全量同步的数据会对数据进行统一的数据类型转换处理再存入数据服务区的每日全量数据分区,针对增量同步的数据会对数据进行统一的数据类型转换处理的同时还会对前一天全量数据和当天的增量数据进行数据合并后再存入数据服区。
进入数据中台ODS层的数据服务区后的数据,可以提供给CDM层或ADS层进行数据加工处理。CDM层会从ODS层的数据服务区获取维度和事实数据经过转换后按照新的数据模型分别存入DIM维度表和DWD明细事实表。基于公共汇总指标的需求,基于CDM层的DIM维度数据和DWD明细事实数据,加工生成汇总统计数据存储DWS汇总事实表。
ADS层的数据一般优先来源于CDM通用数据模型层数据,但对于一些特殊应用的个性化数据需求或复杂数据需求,可直接从ODS层的数据服务层取数据加工后生成ADS层直接面向业务的数据。
最后ADS应用层和CDM公共层的数据同步至数据接口服务层的在线存储产品,通过统一的数据接口服务层,为上层的数据应用和业务系统提供统一的数据服务。
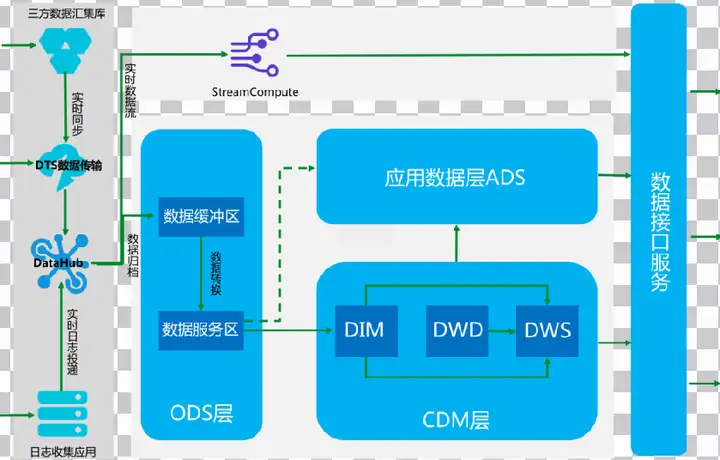
针对不同的数据源,阿里云DTS实时数据传输服务和定制化开发的日志搜集应用,分别从关系数据库和其他数据源类型(如数据API)实时获取数据,将数据实时写入阿里云DataHub存储。
在数据写入DataHub后,针对需要实时计算的业务场景,通过阿里云StreamCompute流计算引擎实时进行运算,将运算后的结果数据,推送到数据接口服务层,提供给数据应用和业务系统使用。
很多场景需要将实时数据流产生的数据保存下来供离线计算使用,采用定期对DataHub的数据进行归档存储到数据中台ODS层的数据缓冲区。数据存入ODS层的数据缓冲区后,后续的数据加工及流转过程和离线数据流相同
DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS平台产品,为您提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks基于MaxCompute作为核心的计算、存储引擎,提供海量数据的离线加工分析、数据挖掘等功能。
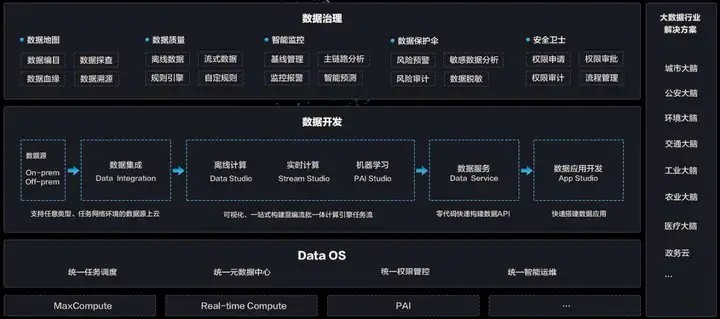
DataWorks提供强大的调度能力,支持根据时间、依赖关系,进行任务触发的机制。同时支持每日千万级别的任务,根据DAG关系准确、准时地运行。支持分钟、小时、天、周和月多种调度周期配置。完全托管的服务,无需关心调度的服务器资源问题。提供隔离功能,确保不同租户之间的任务不会相互影响。
支持多种节点类型。DataWorks支持数据同步、Shell、MaxCompute SQL、MaxCompute MR等多种节点类型,通过节点之间的相互依赖,对复杂的数据进行分析处理。 数据转化:依托MaxCompute强大的能力,保证了大数据的分析处理性能。
据同步:依托DataWorks中数据集成的强力支撑,支持超过20种数据源,为您提供稳定高效的数据传输功能。
可视化开发DataWorks提供可视化的代码开发、工作流设计器页面,无需搭配任何开发工具,简单拖拽和开发,即可完成复杂的数据分析任务。只要有浏览器有网络,便可随时随地进行开发工作。
监控公告运维中心提供可视化的任务监控管理工具,支持以DAG图的形式展示任务运行时的全局情况。
浪潮不可逆,那就跳吧,至于会不会溺水,下去试一试。随手码了几段文字,后续还会持续更新,今天就先到这里。

相关标签:
相关文章推荐

近日,OpenAI 发布的文生视频模型 Sora,能通过文字指令生成逼真、生动的 60 秒长视频,一时间轰动了整个科技圈。从这一镜到底可以看出,视频中的女主角和背景都有着惊人的连贯性和稳定性,包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,甚至与实景拍摄别无二致。不得不让人直呼“王炸技术”!技术原理,其实和ch...

而且,在大模型训练+推理的共同驱动下,因风冷难以适配最新的计算卡,也推动了液冷市场总量与边际增速快速提升,这意味着对于更大规模的机房和数据中心来说,规模效应可以进一步体现,从经济性角度来看,液冷明显比风…...

随着数据中心的需求不断增长,模块化机房建设成为了一种高效、灵活的解决方案。然而,在实施模块化机房建设之前,需要对需求和标准进行充分的了解和评估。 一、模块化机房建设的需求 1.可扩展性 模块化机房建设需要考虑到未来的扩展需求,确保可快速、灵活地对机...

工信部党组在《求是》杂志发表文章《大力推动数字经济和实体经济深度融合》。其中提到,加强数字基础设施建设应用。这是促进数字经济和实体经济深度融合的基石。部署绿色智能的数据与计算设施,支持以高技术、高算力、高能效、高安全为特征的新型数据中心建设,构建“云边端...
“天津中心作为发展新质生产力和促进高质量发展的重要支撑,要成为京津冀科技创新协同和产业体系融合的纽带和桥梁,成为共建京津冀中心开展跨区域、跨领域、跨学科协同创新的组织者,成为推动科技成果从实验室走向生产线,科技教育人才融通发展的促进者”。_新浪网...

财联社8月4日讯(编辑 宣林)据Choice数据统计,截至今日,沪深两市本周共102家上市公司接受机构调研。按行业划分,电子、机械设备和计算机行业接受机构调研频度最高。此外,农林牧渔、家用电器等行业关注度有所提升。 细分领域看,半导体、软件开发和汽车零部件板块位列机构关注度前三名。此外,自动化设备、...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图



