
负载均衡是云计算的基础组件,是网络流量的入口,其重要性不言而喻。
什么是负载均衡呢?将用户请求或者说流量通过负载均衡器,按照某种负载均衡算法把流量均匀地分散到后端的多个服务器上,接收到请求的服务器可以独立的响应请求,以期望的规则分摊到多个操作单元上进行执行,达到负载分担的目的。并通过它可以实现横向扩展(scale out),将冗余的作用发挥为高可用。
从应用场景上来说,常见的负载均衡模型有全局负载均衡和集群内负载均衡,从产品形态角度来说,又可以分为硬件负载均衡和软件负载均衡。
全局负载均衡一般通过 DNS 实现,通过将一个域名解析到不同 VIP,来实现不同的 Region 调度能力。
硬件负载均衡器常见的有 F5、A10、Array,它们的优缺点都比较明显,优点是功能强大,有专门的售后服务团队,性能比较好;缺点是缺少定制的灵活性,维护成本较高。
现在的互联网更多的思路是通过软件负载均衡来实现,这样可以满足各种定制化需求,常见的软件负载均衡有 LVS、Nginx、Haproxy。
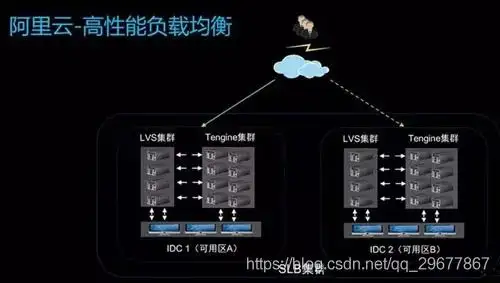
对于用户配置的四层监听,LVS 后面会直接挂载用户 ECS,七层用户监听 ECS 则挂载在 Tengine 上。四层监听的流量直接由 LVS 转发到 ECS,而七层监听的流量会经过 LVS 到 Tenigine 再到用户 ECS。
每一个 Region 里都会有多个可用区,达到主备容灾目的,每一个集群里都有多台设备,第一是为了提升性能,第二也是基于容灾考虑。
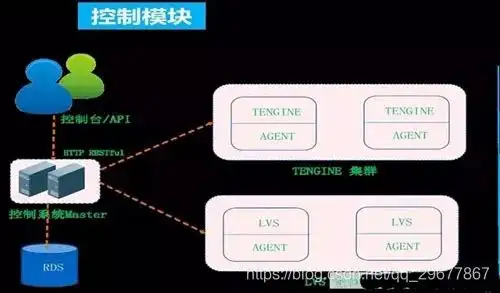
上图为高性能负载均衡控制管理概要图,SLB 产品也有 SDN 概念,转发和控制是分离的,用户所有配置通过控制台先到控制器,通过集中控制器转换将用户配置推送到不同设备上,每台设备上都有 Agent 接收控制器下发的需求。
通过本地转换成 LVS 和 Tengine 能够识别的配置,这个过程支持热配置,不影响用户转发,不需要 reload 才能使新配置生效。
早期 LVS 支持以下三种模式:DR 模式、TUN 模式、NAT 模式
DR 模式经过 LVS 之后,LVS 会将 MAC 地址更改、封装 MAC 头,内层 IP 报文不动。
报文经过 LVS 负载均衡查找到 RS 之后,将源 MAC 头改成自己的,目的 MAC 改成 RS 地址,MAC 寻址是在二层网络里,对网络部署有一定的限定,在大规模分布式集群部署里,这种模式的灵活性没有办法满足需求。
TUN 模式走在 LVS 之后,LVS 会在原有报文基础上封装 IP 头,到了后端 RS 之后,RS 需要解开 IP 报文封装,才能拿到原始报文。
不管是 DR 模式还是 TUN 模式,后端 RS 都可以看到真实客户源 IP,目的 IP 是自己的 VIP,VIP 在 RS 设备上需要配置,这样可以直接绕过 LVS 返回给用户。
TUN 模式问题在于需要在后端 ECS 上配置解封装模块,在 Linux 上已经支持这种模块,但是 Windows 上还没有提供支持,所以会对用户系统镜像选择有限定。
NAT 模式用户访问的是 VIP,LVS 查找完后会将目的 IP 做 DNAT 转换,选择出 RS 地址。
因为客户端的 IP 没变,在回包的时候直接向公网真实客户端 IP 去路由,NAT 的约束是因为 LVS 做了 DNAT 转换,所以回包需要走LVS,把报文头转换回去。
由于 ECS 看到的是客户端真实的源地址,我们需要在用户 ECS 上配置路由,将到 ECS 的默认路由指向 LVS 上,这对用户场景也做了限制。

Netfilter 是 Linux 提供的网络开放平台,基于该平台可以开发自己的业务功能模块,早期好多安全厂商都是基于 Netfilter 做一些业务模型实现。
这种模型比较灵活,但通用模型里更多的是兼容性考虑,路径会非常长;而且通用模型中没办法发挥多核特性,目前 CPU 的发展更多是向横向扩展。
我们经常见到多路服务器,每路上有多少核,早期通用模型对多核支持并不是特别友善,在多核设计上有些欠缺,导致我们在通用模型上做一些应用开发时的扩展性是有限的,随着核的数量越来越多,性能不增反降。
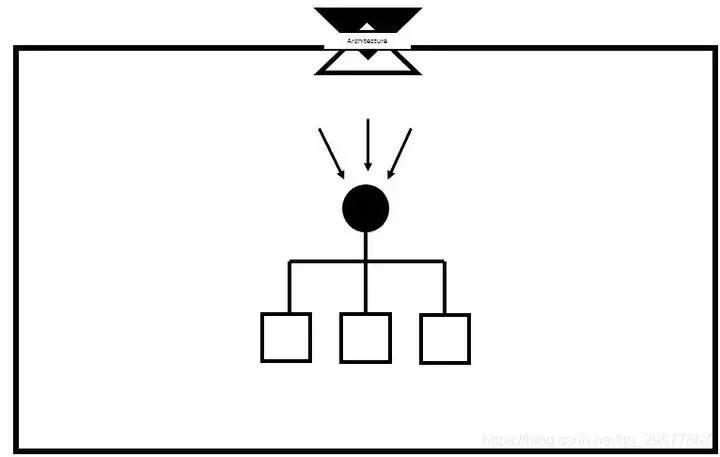
正如上图所示的这样,由一个独立的统一入口来收敛流量,再做二次分发的过程就是负载均衡,它的本质和分布式系统一样,是分治。在软件系统中为了避免流量分摊不均,造成局部节点负载过大(如 CPU 吃紧等),所以引入一个独立的统一入口来做类似的工作。在软件系统中的负载均衡的背后是策略在起作用,而策略的背后是由某些算法或者说逻辑来组成的。负载均衡,也有很多算法或者说逻辑在支撑着这些策略,也有静态和动态之分。
下面来罗列一下日常工作中最常见的 5 种策略。
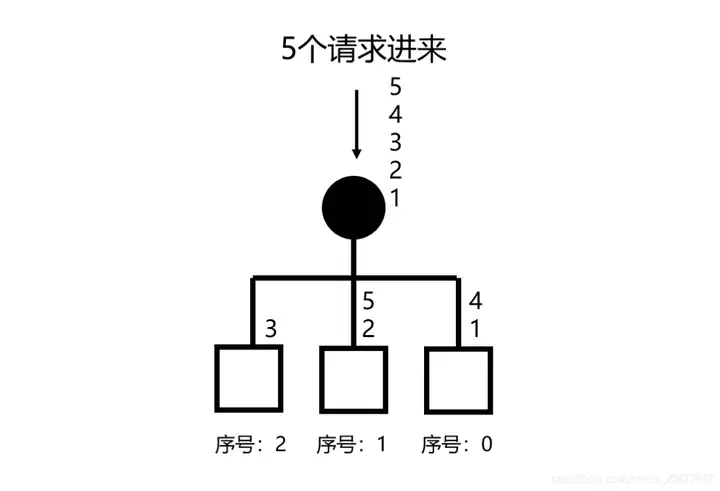
这是最常用也最简单策略,平均分配,人人都有、一人一次。大致的代码如下:
在轮询的基础上,增加了一个权重的概念。权重是一个泛化后的概念,可以用任意方式来体现,本质上是一个能者多劳思想。
比如,可以根据宿主的性能差异配置不同的权重。大致的代码如下:
这段代码的过程如下图的表格。"()"中的数字就是自增数,即代码中的 cur_weight。
值得注意的是,加权轮询本身还有不同的实现方式,虽说最终的比例都是 2:1:2。
但是在请求送达的先后顺序上可以有所不同。比如「5-4,3,2-1」和上面的案例相比,最终比例是一样的,但是效果不同。
「5-4,3,2-1」更容易产生并发问题,导致服务端拥塞,且这个问题随着权重数字越大越严重。
例子:10:5:3 的结果是「18-17-16-15-14-13-12-11-10-9,8-7-6-5-4,3-2-1」
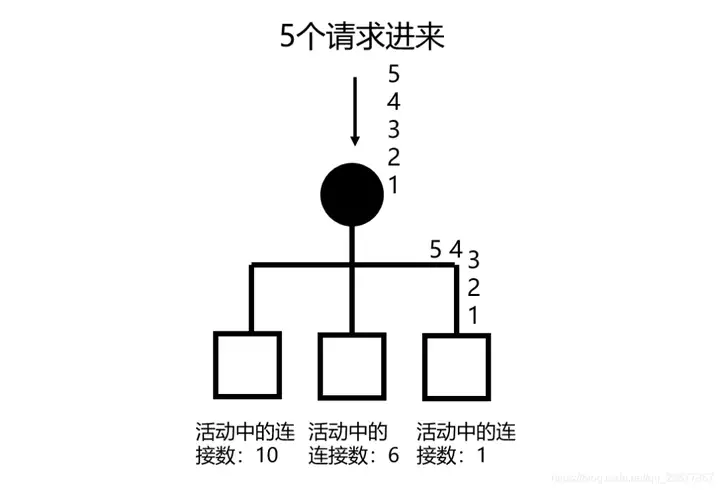
这是一种根据实时的负载情况,进行动态负载均衡的方式。维护好活动中的连接数量,然后取最小的返回即可。大致的代码如下:
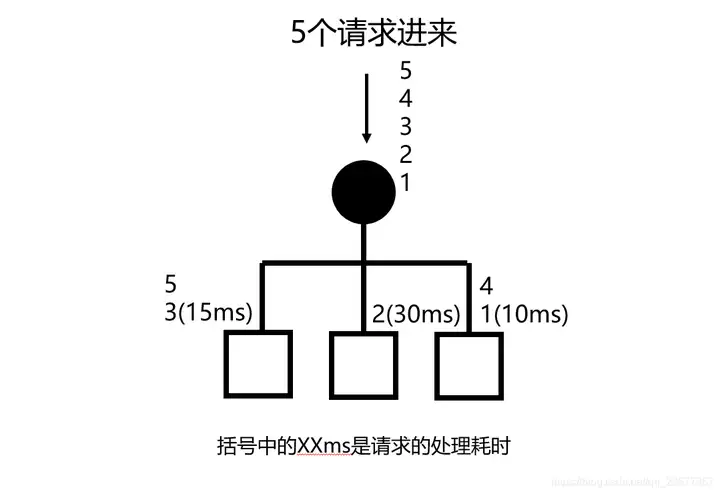
这也是一种动态负载均衡策略,它的本质是根据每个节点对过去一段时间内的响应情况来分配,响应越快分配的越多。
具体的运作方式也有很多,上图的这种可以理解为,将最近一段时间的请求耗时的平均值记录下来,结合前面的加权轮询来处理,所以等价于 2:1:3 的加权轮询。
题外话:一般来说,同机房下的延迟基本没什么差异,响应时间的差异主要在服务的处理能力上。
如果在跨地域(例:浙江->上海,还是浙江->北京)的一些请求处理中运用,大多数情况会使用定时「Ping」的方式来获取延迟情况,因为是 OSI 的 L3 转发,数据更干净,准确性更高。
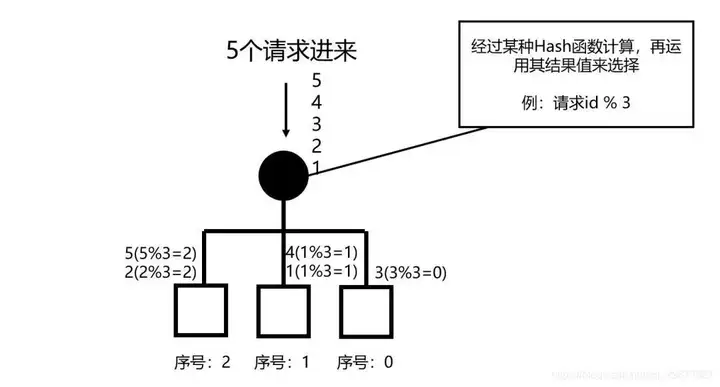
Hash 法的负载均衡与之前的几种不同在于,它的结果是由客户端决定的。通过客户端带来的某个标识经过一个标准化的散列函数进行打散分摊。上图中的散列函数运用的是最简单粗暴的取余法。
题外话:散列函数除了取余之外,还有诸如变基、折叠、平方取中法等等,此处不做展开,有兴趣的小伙伴可自行查阅资料。
另外,被求余的参数其实可以是任意的,只要最终转化成一个整数参与运算即可。
最常用的应该是用来源 IP 地址作为参数,这样可以确保相同的客户端请求尽可能落在同一台服务器上。
常用负载均衡策略优缺点和适用场景
我们知道,没有完美的事物,负载均衡策略也是一样。上面列举的这些最常用的策略也有各自的优缺点和适用场景,我稍作了整理,如下。

这些负载均衡算法之所以常用也是因为简单,想要更优的效果,必然就需要更高的复杂度。
比如,可以将简单的策略组合使用、或者通过更多维度的数据采样来综合评估、甚至是基于进行数据挖掘后的预测算法来做。
不管是什么样的策略,难免会遇到机器故障或者程序故障的情况。所以要确保负载均衡能更好的起到效果,还需要结合一些健康探测机制。定时的去探测服务端是不是还能连上,响应是不是超出预期的慢。
如果节点属于“不可用”的状态的话,需要将这个节点临时从待选取列表中移除,以提高可用性。一般常用的健康探测方式有 3 种。
使用 Get/Post 的方式请求服务端的某个固定的 URL,判断返回的内容是否符合预期。一般使用 HTTP 状态码、Response 中的内容来判断。
基于 TCP 的三次握手机制来探测指定的 IP + 端口。最佳实践可以借鉴阿里云的 SLB 机制,如下图:
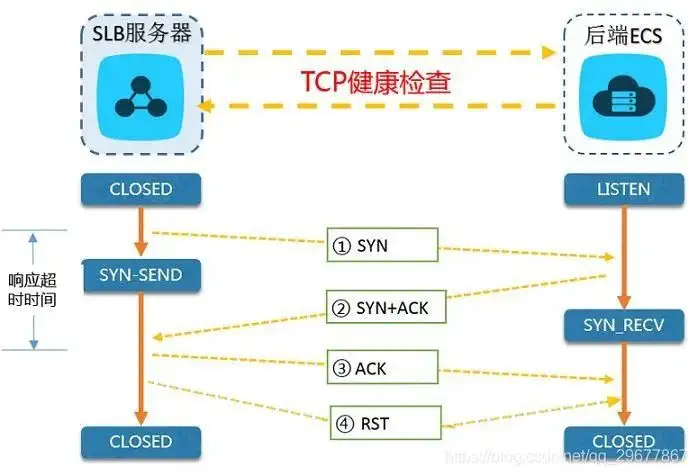
值得注意的是,为了尽早释放连接,在三次握手结束后立马跟上 RST 来中断 TCP 连接。
可能有部分应用使用的是 UDP 协议。在此协议下可以通过报文来进行探测指定的 IP + 端口。最佳实践同样可以借鉴阿里云的 SLB 机制,如下图:
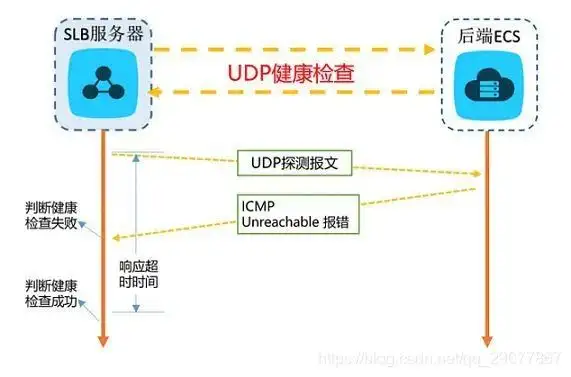
结果的判定方式是:在服务端没有返回任何信息的情况下,默认是正常状态。否则会返回一个 ICMP 的报错信息。
链接:https://blog.csdn.net/qq_29677867/article/details/90050721(版权归原作者所有,侵删)相关标签:
相关文章推荐

最近Synergy研究院发布了最新的全球云计算市场份额排名:亚马逊依旧是以31%的的市场份额排名第一,微软azure24%排名第二,Google云11%排名第三,阿里云4%排名第四。腾讯云和IBM、甲骨文并列2%。通过上面的图片也可以判断出:(1)云市场的格局基本已定,这几年也没啥变化,增量市场变为存量市场了,企业迁移云的成本巨大,这就...
钛媒体旗下的钛坦白微信课第26期,请来了8位对“企业上云”有深刻理解的钛客进行分享。本文根据金山云网络与安全部技术总监刘涛的分享整理。刘涛是通信...
原标题:美国国家安全局(NSA)窃听站 美国国家安全局(NSA)的秘密据点隐藏在美国各地的城市中,那些高耸的没有窗户的摩天大楼和足以抵御地震,甚至核攻击。成千上万的人每天经过这些建筑物,很少再给他们看第二眼,因为他们的功能并未公开。它们是全球最大的电信网络中不可分割的一部分,它们也与有争议的国家...

在USB 80Gbps(原来的USB4 v2.0)正式公布后,Intel也首次预览了下一代雷电接口。 Intel暂时没有使用“雷电5”的说法,但从多年惯例来看,应该跑不了。 “雷电5”号称可以有着3倍雷电4的速度,也就是120Gbps,不过这是一种特殊模式,主要用于单线连接高端显示器等场景,借助PAM3调制技术,可实现上行120G...

俄罗斯外交部指出,任何国家向乌克兰提供武器是在“玩火”。 据乌克兰通讯社17日报道,连接俄罗斯南部与克里米亚半岛的克里米亚大桥当天传出“爆炸声”,已有2人死亡,1人受伤。 不久前,美国的集束炸弹运抵乌克兰。俄乌局势再起波澜,这场旷日持久的冲突,究竟何去何从? 当地时间16日,据俄罗斯卫星通讯...

“云网融合”成为当前信息通信领域的热门话题,“云”即是云计算,包括计算能力、存储能力、数据分析和应用能力等;“网”则是连接与传送能力,包括通信网络中的接入网、承载网、核心网等。随着5G网络的建设与深入…...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图

