
2020年4月16日,2020年软件定义存储线上峰会第二天,青云QingCloud资深解决方案架构师张忠华,分享了对象存储在无人驾驶所需的高精度地图上的场景实践,介绍了QingStor®️对象存储的种种优势以及许多针对该场景的特性,在面对特殊的数据处理需求时,QingStor®️对象存储在架构上的许多创新也令人印象深刻。
无人驾驶为什么如此依赖高精度地图
许多人都知道无人驾驶,也没几个人不知道地图,但高精度地图并不是谁都知道的,简单说,高精度地图不是给人看的,而是给自动驾驶的汽车来用的,它和我们日常使用的二地图差异非常大,它包含的信息也也更复杂。
无人驾驶主要分为四个阶段,感知、定位、决策和控制。感知阶段中,车辆依靠车载传感器获取道路与环境信息,然而,在实际情况中,由于天气、环境存在非常大的不确定性,仅仅依靠传感器是无法实现自动驾驶的。每种传感器都有各自的感知缺陷和限制,激光传感器,高分辨率摄像机都会受到干扰,还都会有检测盲区。
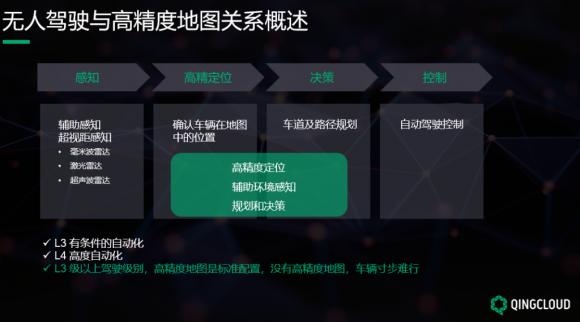
高精度地图就是为了解决这些问题,在无人驾驶第二阶段定位和第三阶段车辆的行使决策阶段,都高度依赖高精度地图来做出决策,高精度地图对于无人驾驶来说是非常的重要。L3 级以上驾驶级别,高精度地图是标准配置,没有高精度地图,车辆寸步难行。
这就是高精度地图和自动驾驶的关系,那么高精度地图到底包含哪些具体的信息呢?
原来,高精度地图必须包含两类数据:
第一类,道路本身的数据,比如车道线位置、类型、宽度、坡度和曲率道路信息;
第二类,环境信息,比如交通标志,信号灯,限行信息,路边地标等基础设施信息。
由此可见,高精度地图包含的信息是非常复杂和多样的。
由于地图采集设备的精度不同,产生的数据大小也会不同,但可以看出,高精度地图数据的体量极为庞大,一辆标准的数据采集车大概有4到5个传感器,每台数据采集车每天可采集百公里左右路程,大约会产生一个TB的数据。
对于高精度地图而言,采集和制图,只是完成了无人驾驶地图制作过程的10%的工作量,后期地图长期的更新,可能需要占90%的工作量,地图的更新一般都会采用车队学习网络(Fleet Learning Network),类似于P2P,每辆车最终都是地图数据贡献者,也是资源的享用者,特斯拉用的就是这种地图的更新模式。
在无人驾驶汽车正式量产后,上路行使时需要全天候不停读取地图数据,更大的压力来自于实时地图数据的更新。在后期地图更新中,数据采集车带来的大量数据并发压力是非常大的。
高精度地图和QingStor®️ 对象存储

张忠华详细介绍了QingStor®️ 对象存储在高精度地图场景中的应用。
高精度地图的制作流程可以分为四个步骤:经过采集和预处理后,数据会写入到对象存储中,之后由对象存储将数据输出到AI超级训练一体机,比如英伟达DGX-1,由训练一体机做复杂的数据处理,超级训练一体机性能非常强大,但面对采集到的海量数据,处理能力也会捉襟见肘,在它完成处理之前,采集到的数据仍需要存储在对象存储中,训练完成后,数据需要写回到对象存储做长期留存。
在这一场景中,对象存储贯穿了整个高精度地图的全部制作过程,负责海量地图数据的转储以及后期地图长期存储,目前QingStor®️对象存储在这一个场景中整体数据规模已经有10个PB,预估在三年后,总体规模会达到40PB。

在这样的场景中,QingStor®️对象存储有一个具体的数据流架构图,图中可见,当数据由数据采集车完成以后,会通过程序接口将数据写入到对象存储中,再由AI训练一体机DGX-1处理对象存储中的数据,处理完成的数据再入对象存储。
该场景部署了单一全局统一命名空间的对象存储集群,从架构上看,它并不复杂,唯一需要特别关注的点是使用对象存储场景中,业务部门需要有一定的接口开发和对接的能力。在实际应用场景,高精度地图对对象存储也带来了不少挑战。
高精度地图带来的挑战以及对象存储的应对之道
首先一大挑战是对性能和空间需求不确定性的挑战,在地图的前期制作过程中,采集车的数量是相对固定的,数据生成量也相对固定,从业务形态上来看,并发压力也相对固定。然而,后期地图更新则可能会导致较大并发,并发访问压力和数据写入压力变化比较大。

面对这一情况,QingStor®️对象存储采用了分层设计架构,主要核心的存储平台分为接入子系统和索引子系统以及负责具体数据存储的存储子系统,这样就可以单独根据并发压力和存储空间需求进行单独扩展,而且不同角色的服务器节点还可以使用不同的配置,从而物尽其用,不浪费资源。

第二个挑战在于数据安全和服务可靠性。由于自动驾驶过程中对地图依赖度比较高,对于数据访问可靠性的要求极高,但是分布式存储在海量存储场景下,在有节点故障或者扩容时都需要对数据进行重构和平衡,对数据进行重构和平衡的出发点是好的,它可以让节点的负载更加均衡,但在超大规模的数据场景下,在局部的新增和删除可能都会对集群产生影响,如何避免对于数据访问可靠性的影响呢?
QingStor®️对象存储将庞大的存储集群分成若干个存储服务器小组来缩小故障域,不同的存储组之间毫无关联,他们只接收来自接入层的服务调度。
当有节点故障时,只会对同组的三个节点有影响,不会影响到别的存储组,从而避免对整个集群的影响。当需要扩容时,优先写入新扩容的节点,只将数据写入优先级权重比较大的存储组中,旧存储组的数据不做任何变动。这样就规避了对于超大规模集群的影响。

第三个挑战在于数据类型的多样性。地图采集的数据类型非常丰富,常规存储都会对数据进行固定分片,分片一定在程度上是会影响存储效率的。QingStor®️对象存储不做分片,用户可以设定在一定范围内的数据都不做任何处理,直接生成副本,让用户按照需求设置,从而保证不同类型和大小文件的存储效率。

第四个挑战来自于数据交互平台的多样性,地图的制作过程中会涉及多个地图制作平台和软件,涉及到多种开发语言接口,QingStor®️对象存储的SDK支持大多数语言,除了支持S3之外,还支持许多青云QingCloud自有的API接口。
由于此类场景会涉及数据迁移和导入导出,所以,也需要对象存储支持多种数据迁移工具,QingStor®️对象存储支持业界主流的云厂商对象存储,可以提供工具在这些平台之间自定义数据源和数据目标。
QingStor®️对象存储带来的收益和价值

QingStor®️对象存储在高精度地图场景中表现出的价值主要有四点:
第一,较高的ROI回报,分层架构的设计,可以支持用户根据业务需求进行扩容,可以减少资源浪费问题。
第二点,QingStor®️对象存储技术架构非常成熟,经过了大规模公有云平台验证,用户不需要考虑太多的存储平台层的设计,只需专注在业务上。
第三点,较高的性价比,目前QingStor®️对象存储应用较为普遍,除了今天说的用在无人驾驶领域,在大数据分析平台上也能作为大数据平台的数据存储,可以作为数据源和数据存储目标,用一套平台实现多种用途,降低整体的TCO。
第四点,极低的运维成本,QingStor®️对象存储作为一款稳定的商业级产品,拥有完善的服务技术支持团队,如果出现一些问题,技术团队会在第一时间做除响应,对用户来说,大规模数据集场景中只需要很少的运维人员,用户反映说,在运维上的投入非常少,不需要运维人员具备非常深厚的知识。
QingStor®️对象存储有大规模服务的经验,在产品上有许多非常有针对性的特性和服务,在生态上,与业界很多厂商做了一些联合解决方案。

QingStor®️企业级分布式存储家族除了有对象存储,还有文件存储和块存储,作为一个独立的存储产品线,可以脱离公有云,进行私有化部署。如今的QingStor®️企业级分布式存储广泛地服务于银行、保险、能源、制造、医疗和传媒等行业。QingStor®️用基于x86的软件定义存储可以帮助传统企业降低TCO,同时加速传统企业的数字化转型升级。
相关标签:
相关文章推荐

最近Synergy研究院发布了最新的全球云计算市场份额排名:亚马逊依旧是以31%的的市场份额排名第一,微软azure24%排名第二,Google云11%排名第三,阿里云4%排名第四。腾讯云和IBM、甲骨文并列2%。通过上面的图片也可以判断出:(1)云市场的格局基本已定,这几年也没啥变化,增量市场变为存量市场了,企业迁移云的成本巨大,这就...
钛媒体旗下的钛坦白微信课第26期,请来了8位对“企业上云”有深刻理解的钛客进行分享。本文根据金山云网络与安全部技术总监刘涛的分享整理。刘涛是通信...
原标题:美国国家安全局(NSA)窃听站 美国国家安全局(NSA)的秘密据点隐藏在美国各地的城市中,那些高耸的没有窗户的摩天大楼和足以抵御地震,甚至核攻击。成千上万的人每天经过这些建筑物,很少再给他们看第二眼,因为他们的功能并未公开。它们是全球最大的电信网络中不可分割的一部分,它们也与有争议的国家...

在USB 80Gbps(原来的USB4 v2.0)正式公布后,Intel也首次预览了下一代雷电接口。 Intel暂时没有使用“雷电5”的说法,但从多年惯例来看,应该跑不了。 “雷电5”号称可以有着3倍雷电4的速度,也就是120Gbps,不过这是一种特殊模式,主要用于单线连接高端显示器等场景,借助PAM3调制技术,可实现上行120G...

俄罗斯外交部指出,任何国家向乌克兰提供武器是在“玩火”。 据乌克兰通讯社17日报道,连接俄罗斯南部与克里米亚半岛的克里米亚大桥当天传出“爆炸声”,已有2人死亡,1人受伤。 不久前,美国的集束炸弹运抵乌克兰。俄乌局势再起波澜,这场旷日持久的冲突,究竟何去何从? 当地时间16日,据俄罗斯卫星通讯...

“云网融合”成为当前信息通信领域的热门话题,“云”即是云计算,包括计算能力、存储能力、数据分析和应用能力等;“网”则是连接与传送能力,包括通信网络中的接入网、承载网、核心网等。随着5G网络的建设与深入…...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图

