原标题:LLM大模型向量数据库技术架构浅析
AI 智能时代,开发者需要一个真正的向量数据库吗?
答案很简单,这取决于开发者的应用场景。举个例子,晚饭选择去一家五星级餐厅用餐或是是快餐店,往往和你的胃口和期望有关。
如果只是想简单解决一顿饭,一家快餐店就能满足你。同理,如果想为自己的个人网站快速搭建一个问答机器人,或者为相册里的十万张照片建立一个索引,你可以选择最熟悉和便捷的方法,无论是使用免费的向量检索云服务,或者安装基于 PostgreSQL 的开源向量检索插件 PG Vector,抑或是在本地通过 pip 安装 Faiss、HNSW、Annoy 等开源向量检索库,都是不错的选择。
然而,如果我们的目标是一个品质高端的晚宴,大概率会选择一个五星级餐厅。这就好像我们想要构建一个企业级的向量检索应用,数据量超过千万级,要求延迟在 10ms 以下,需要使用高级功能如标量过滤、动态架构、多租户、实时更新/删除、批量导入等。不止如此,我们甚至希望能够在短短十分钟内快速构建一个可用的 Demo……这就不得不借助原生向量数据库的能力和优势了,它就像五星级餐厅一般,不仅可以满足你的基本需求,更是质量和服务的保证。

什么是向量检索?
向量数据库具有快速计算向量相似度的优势,能在 N 个向量中找出与目标向量在高维空间中最相似的前 K 个向量。然而,这种能力并非仅有向量数据库所具备。例如,我们可以通过使用 Python 的 NumPy 库,用不到 20 行代码就能实现最近邻算法。
我们可以试着生成 100 个 2 维向量,然后找出与向量[0.5,0.5]最近的邻居。
向量数据库的底层技术
向量数据库底层技术已经被研究多年,有以下3点关键技术:
第一、基于嵌入的检索( Embedding-Based Retrieval, EBR)已经被研究了十多年。
第二、相似性搜索(Similarity Search)持续了长达半个世纪。
第三、NumPy 或其他 FAISS 向量搜索库也可以用来构建向量搜索系统。
为什么最近向量数据库变成如此火热,推动力就是 LLM 大语言模型。推动从算法向应用系统转变的,是新的「数据密集型应用程序」 = 大量的「非结构化」数据存储 + 「可靠、安全、快速和可伸缩」的查询处理能力。
传统数据库以行和列的表格式存储数据,并且基于精确匹配或预定义条件搜索精确的数据。
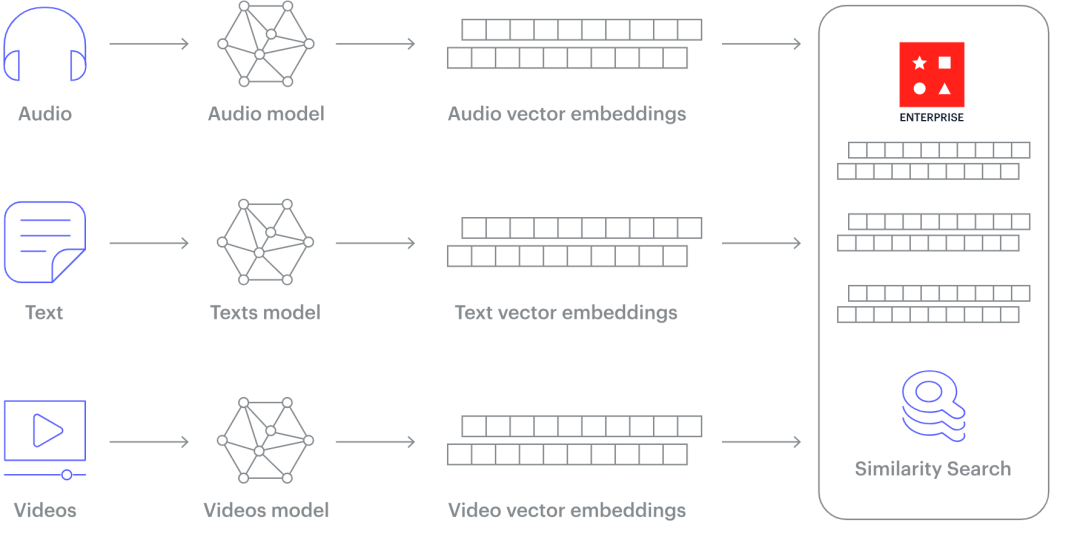
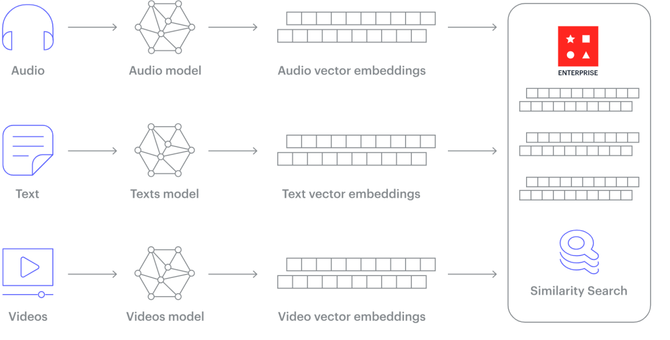
然而,大量业务数据是非结构化的,以文本、图像、音频、视频或其他格式存储,这给传统数据库带来了挑战。
Vector Database 存储的“向量数据”,通常是通过对这些非结构化数据使用某种转换或嵌入函数来生成的。
责任编辑:
相关标签:
相关文章推荐

最近Synergy研究院发布了最新的全球云计算市场份额排名:亚马逊依旧是以31%的的市场份额排名第一,微软azure24%排名第二,Google云11%排名第三,阿里云4%排名第四。腾讯云和IBM、甲骨文并列2%。通过上面的图片也可以判断出:(1)云市场的格局基本已定,这几年也没啥变化,增量市场变为存量市场了,企业迁移云的成本巨大,这就...
钛媒体旗下的钛坦白微信课第26期,请来了8位对“企业上云”有深刻理解的钛客进行分享。本文根据金山云网络与安全部技术总监刘涛的分享整理。刘涛是通信...
原标题:美国国家安全局(NSA)窃听站 美国国家安全局(NSA)的秘密据点隐藏在美国各地的城市中,那些高耸的没有窗户的摩天大楼和足以抵御地震,甚至核攻击。成千上万的人每天经过这些建筑物,很少再给他们看第二眼,因为他们的功能并未公开。它们是全球最大的电信网络中不可分割的一部分,它们也与有争议的国家...

在USB 80Gbps(原来的USB4 v2.0)正式公布后,Intel也首次预览了下一代雷电接口。 Intel暂时没有使用“雷电5”的说法,但从多年惯例来看,应该跑不了。 “雷电5”号称可以有着3倍雷电4的速度,也就是120Gbps,不过这是一种特殊模式,主要用于单线连接高端显示器等场景,借助PAM3调制技术,可实现上行120G...

俄罗斯外交部指出,任何国家向乌克兰提供武器是在“玩火”。 据乌克兰通讯社17日报道,连接俄罗斯南部与克里米亚半岛的克里米亚大桥当天传出“爆炸声”,已有2人死亡,1人受伤。 不久前,美国的集束炸弹运抵乌克兰。俄乌局势再起波澜,这场旷日持久的冲突,究竟何去何从? 当地时间16日,据俄罗斯卫星通讯...

“云网融合”成为当前信息通信领域的热门话题,“云”即是云计算,包括计算能力、存储能力、数据分析和应用能力等;“网”则是连接与传送能力,包括通信网络中的接入网、承载网、核心网等。随着5G网络的建设与深入…...
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 联系QQ:381708881 请注明来意! Copyright © 2023 IDC导航 All Rights Reserved. 蜀ICP备2022025146号-3 XML地图